Artificial Intelligence has moved from research labs into everyday life at breathtaking speed. Just a few years ago, generating human-like text, writing code, creating images from prompts, or analyzing screenshots felt futuristic. Today, Large Language Models, commonly called LLMs, power search engines, coding assistants, business tools, and creative platforms used by millions.
But behind the polished chat interfaces lies a fascinating engineering story.
How are these massive AI systems actually built? Why do some models specialize in reasoning while others excel at conversation or image generation? What changed between GPT-1 and GPT-4? Why are architectures like BERT, T5, PaLM, and LLaMA so influential? And what exactly are Mixture of Experts and multimodal models?
This article takes a practical, engineering-first journey into modern LLMs. We’ll explore how they are trained at scale, compare major architectures, examine their trade-offs, and walk through examples that make the concepts intuitive.
The Foundation: What Is an LLM?
At its core, a Large Language Model predicts the next token in a sequence.
A token may be:
- A word
- Part of a word
- Punctuation
- Special symbols
For example:
Input: “The capital of France is”
Prediction: “Paris”
That simple objective scales into extraordinary capabilities when trained on enormous datasets.
Modern LLMs learn:
- Grammar
- Reasoning patterns
- Coding syntax
- World knowledge
- Writing styles
- Translation
- Problem solving
The Big Breakthrough: Transformers
Before transformers, AI relied heavily on RNNs and LSTMs.
Those models processed words sequentially:
Word 1 → Word 2 → Word 3 → Word 4
This caused major bottlenecks:
- Slow training
- Difficulty remembering long context
- Poor parallelization
Then came the transformer architecture in 2017 through the famous paper:
“Attention Is All You Need”
Transformers introduced self-attention, allowing models to process all tokens simultaneously.
Instead of reading sentence-by-sentence like humans, transformers calculate relationships between all words at once.
For example:
“The animal didn’t cross the street because it was tired.”
The model learns that “it” refers to “animal.”
That contextual understanding changed everything.
Understanding Self-Attention Intuitively
Imagine you’re reading a sentence while highlighting important words related to the current word.
Example sentence:
“John gave Sarah a book because she loves reading.”
When processing “she,” the model pays more attention to:
- Sarah
- loves
- reading
Less attention goes to:
- gave
- book
This weighted relationship is called attention.
The attention score is computed mathematically using:
- Query Vectors
- Key Vectors
- Value Vectors
The simplified formula:
This mechanism enables transformers to understand context incredibly well.
How LLMs Are Trained at Scale
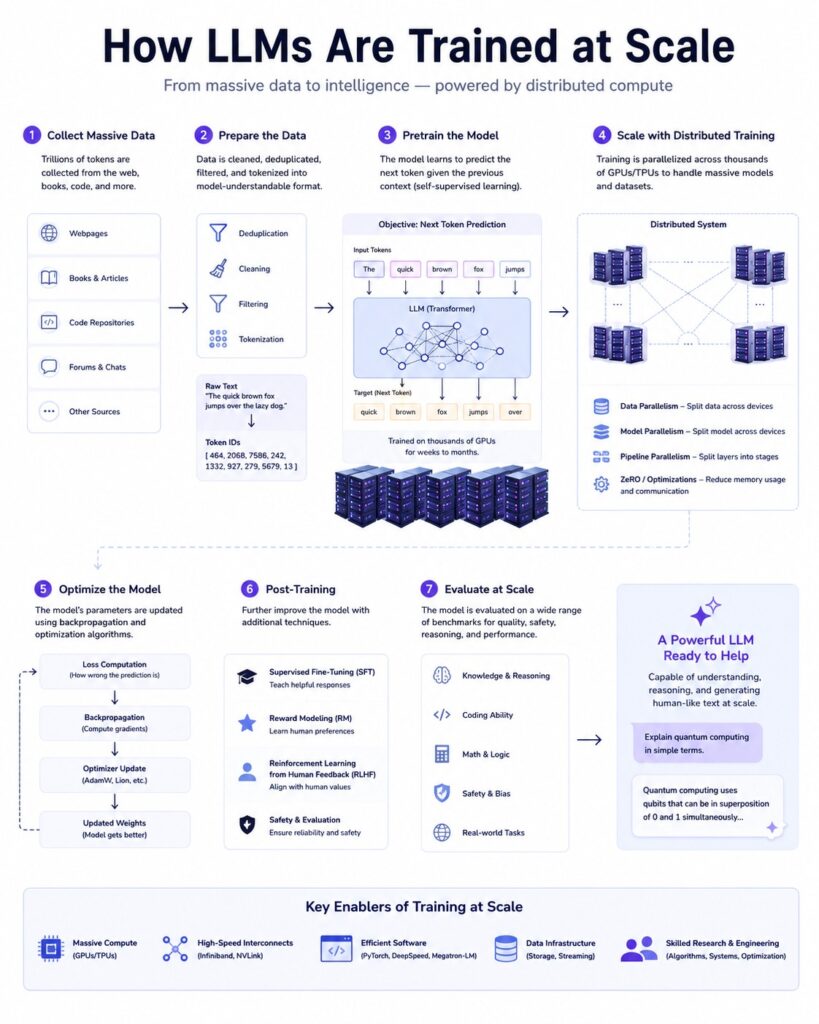
Fig 1. Training LLMs at Scale
Training an LLM is one of the most computationally expensive tasks in technology today.
A modern model may require:
- Trillions of tokens
- Thousands of GPUs
- Weeks or months of training
- Massive distributed systems
The process generally looks like this:
- Collect Data
- Clean & Filter Data
- Tokenization
- Pretraining
- Fine-tuning
- Alignment & Safety
- Deployment
Let’s unpack this.
Step 1: Data Collection
LLMs are trained on gigantic datasets collected from:
- Websites
- Books
- Academic papers
- Code repositories
- Wikipedia
- Forums
- Documentation
Example datasets include:
- Common Crawl
- The Pile
- C4
- GitHub repositories
The quality of data matters enormously.
Poor data leads to:
- Hallucinations
- Toxic outputs
- Bias
- Weak reasoning
This is why modern AI companies invest heavily in filtering pipelines.
Step 2: Tokenization
Computers don’t understand words directly.
Text gets converted into tokens.
Example:
text = “Transformers are powerful”
tokens = [“Transform”, “ers”, “are”, “powerful”]
Popular tokenization methods:
- Byte Pair Encoding (BPE)
- SentencePiece
- WordPiece
Tokenization dramatically affects:
- Vocabulary size
- Memory efficiency
- Multilingual performance
Step 3: Pretraining
This is where the magic happens.
The model repeatedly predicts missing or next tokens across billions of examples.
Example training sample:
Input:
“The sky is”
Target:
“blue”
Over time, the model learns language structure statistically.
A simplified PyTorch example:
import torch import torch.nn as nn class TinyLM(nn.Module): def __init__(self, vocab_size, embed_dim): super().__init__() self.embedding = nn.Embedding(vocab_size, embed_dim) self.linear = nn.Linear(embed_dim, vocab_size) def forward(self, x): x = self.embedding(x) return self.linear(x) model = TinyLM(10000, 256)
Real-world models scale this idea enormously.
GPT-4 likely contains trillions of parameters or uses advanced sparse architectures.
Scaling Laws: Bigger Models Actually Work Better
One fascinating discovery in AI research is scaling laws.
As you increase:
- Parameters
- Data
- Compute
Performance improves predictably.
This relationship became foundational to modern AI development.
A simplified intuition:
This insight motivated companies to build larger and larger models.
But scaling creates challenges:
- GPU memory limits
- Network bottlenecks
- Training instability
- Power consumption
- Cost explosions
Training frontier models can cost tens or hundreds of millions of dollars.
Distributed Training: The Real Engineering Challenge
A single GPU cannot train a modern LLM.
Engineers split training across thousands of GPUs using techniques like:
Data Parallelism
Each GPU trains on different batches.
GPU 1 → Batch A
GPU 2 → Batch B
GPU 3 → Batch C
Gradients are synchronized afterward.
Tensor Parallelism
Large matrices are split across GPUs.
Example:
Matrix A split into:
GPU 1 → Left half
GPU 2 → Right half
Pipeline Parallelism
Different layers live on different GPUs.
GPU 1 → Layers 1-10
GPU 2 → Layers 11-20
GPU 3 → Layers 21-30
This enables training models too large for a single machine, distributed systems and scalable infrastructure.
GPT Family Evolution: From GPT-1 to GPT-4
The GPT family dramatically shaped the AI landscape.
Let’s examine how it evolved.
GPT-1: The Proof of Concept
Released in 2018.
Key ideas:
- Transformer decoder architecture
- Unsupervised pretraining
- Fine-tuning for downstream tasks
Size:
- 117 million parameters
At the time, this was revolutionary.
GPT-1 proved that generic language pretraining works.
GPT-2: The Internet Was Shocked
Released in 2019.
Size:
- 1.5 billion parameters
Capabilities improved dramatically:
- Long coherent text
- Story writing
- Summarization
- Question answering
OpenAI initially delayed full release due to misuse concerns.
Example GPT-2 generation:
Prompt:
“In a shocking discovery…”
Output:
“In a shocking discovery, scientists found…”
This was the first time many people felt AI-generated text was genuinely convincing.
GPT-3: Emergent Intelligence
Released in 2020.
Size:
- 175 billion parameters
GPT-3 introduced:
- Few-shot learning
- In-context learning
- Better reasoning
- In-context learning
- Code generation
- Few-shot learning
- In-context learning
- Better reasoning
- In-context learning
- Code generation
The major breakthrough:
You no longer needed task-specific fine-tuning.
Example:
Translate English to French:
Dog → Chien
Cat → Chat
House →
The model infers the task dynamically.
This changed how developers built AI applications.
GPT-3.5: The Chat Revolution
GPT-3.5 powered the initial viral wave of ChatGPT.
Major improvements:
- Conversational tuning
- Reinforcement Learning from Human Feedback (RLHF)
- Better instruction following
RLHF became a critical innovation.
Process:
- Human rankings
- Reward model
- Policy optimization
This alignment process made models significantly more helpful and safer.
GPT-4: Multimodal and More Reliable
GPT-4 represented another leap.
Key improvements:
- Better reasoning
- Multimodal capabilities
- Stronger factuality
- Longer context windows
- Improved coding ability
GPT-4 can analyze:
- Images
- Charts
- UI screenshots
- Documents
This moved LLMs beyond pure text systems.
Decoder-Only vs Encoder Models
Different architectures optimize for different goals.
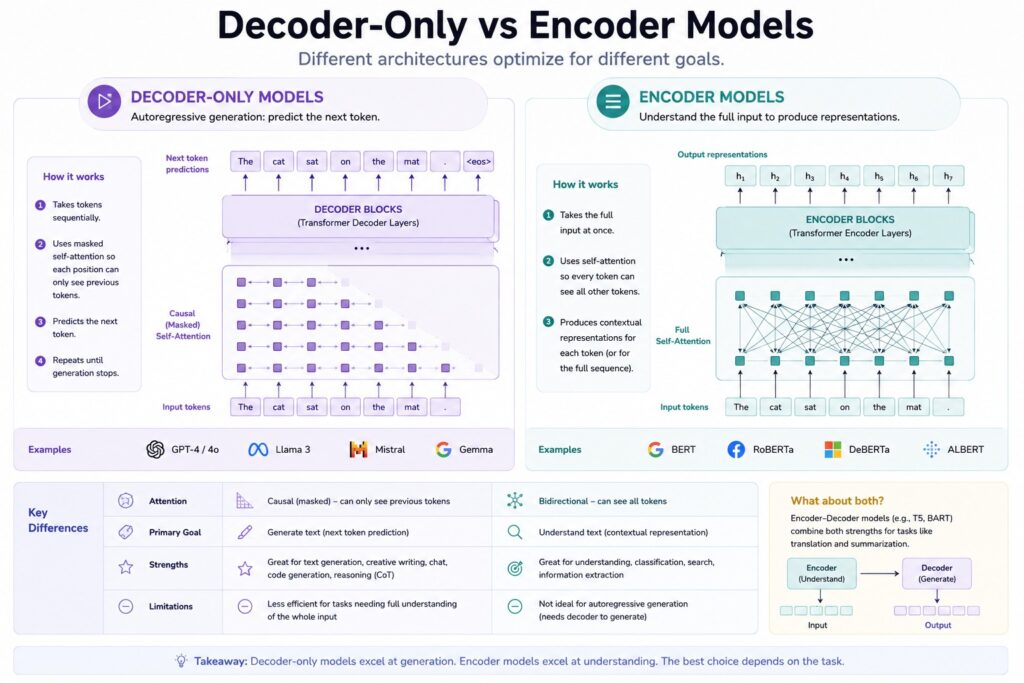
Fig 2. Decoder-Only vs Encoder Models
GPT Style: Decoder-Only
GPT models predict the next token sequentially.
Architecture strengths:
- Text generation
- Chatbots
- Coding assistants (full-stack AI application development)
- Creative writing
Weaknesses:
- Less efficient for classification
- Slower bidirectional understanding
BERT: Bidirectional Understanding
Google introduced BERT in 2018.
BERT reads text in both directions simultaneously.
Instead of predicting next words, BERT predicts masked words.
Example:
“The cat sat on the [MASK].”
Prediction:
mat
This enables deep contextual understanding.
BERT became dominant for:
- Search ranking
- Sentiment analysis ( real-world data analytics and NLP workflows )
- Entity recognition
- Classification
Why BERT Changed NLP
Before BERT, models usually read left-to-right.
BERT introduced fully bidirectional attention.
That improved language understanding dramatically.
Simple Hugging Face example:
from transformers import pipeline
classifier = pipeline(“sentiment-analysis”)
result = classifier(“This movie was fantastic!”)
print(result)
BERT-based systems became foundational in enterprise NLP.
T5: Text-to-Text Transfer Transformer
Google’s T5 unified NLP tasks into a single format.
Everything became text input → text output.
Examples:
translate English to German: Hello
→ Hallo
summarize: Long article…
→ Summary
question: What is AI?
→ Artificial Intelligence
This simplicity made T5 extremely flexible.
Why T5 Was Important
Instead of designing separate architectures for each task:
- Translation
- Summarization
- QA
- Classification
T5 handled everything uniformly.
That inspired many later instruction-tuned models.
PaLM: Scaling to Massive Intelligence
Google’s PaLM pushed scaling further.
Highlights:
- 540 billion parameters
- Advanced few-shot learning
- Better reasoning
- Chain-of-thought prompting
Example reasoning prompt:
Q: Roger has 5 apples and buys 3 more.
How many apples does he have?
Let’s think step by step.
That phrase often dramatically improves reasoning quality.
This revealed that prompting itself became an important engineering discipline.
LLaMA: Open Models Changed the Ecosystem
Meta’s LLaMA models transformed open-source AI.
Why they mattered:
- Smaller but highly efficient
- Strong performance per parameter
- Open research ecosystem
LLaMA enabled:
- Local AI applications
- Fine-tuning by startups
- Research democratization
Soon the ecosystem exploded with:
- Alpaca
- Vicuna
- Mistral
- Orca
- Mixtral
The open-source AI race accelerated rapidly.
Parameter Efficiency Matters
Bigger isn’t always better.
A well-trained 7B parameter model can outperform poorly trained larger models.
Key optimization areas:
- Data quality
- Training tokens
- Fine-tuning methods
- Architecture design
- Alignment techniques
This shifted focus from raw size to efficiency.
Mixture of Experts: Smarter Scaling
One major challenge with huge models:
Every parameter activates for every token.
That is expensive.
Mixture of Experts (MoE) solves this elegantly.
Instead of activating the full model:
- Only specialized sub-networks activate per token.
Imagine a hospital:
- Cardiologist handles heart issues
- Neurologist handles brain issues
- Orthopedic specialist handles bones
Similarly, MoE routes tasks to specialized experts.
How Mixture of Experts Works
Architecture:
- Input
- Router
- Selected Experts
- Output
Only a few experts process each token.
Benefits:
- Lower compute cost
- Massive parameter scaling
- Better specialization
Trade-offs:
- Training instability
- Load balancing complexity
- Routing overhead
Sparse Activation Explained
Traditional dense model:
All neurons active every time
MoE model:
Only relevant experts activate
This enables trillion-parameter systems without trillion-parameter compute costs.
Famous MoE models include:
- Switch Transformer
- Mixtral
- GPT-4 variants (speculated)
Practical MoE Pseudocode
def router(token): if "code" in token: return coding_expert elif "math" in token: return math_expert else: return general_expert
Real systems use learned routing networks instead of manual rules.
Multimodal Models: Beyond Text
Modern AI increasingly combines:
These are called multimodal models.
CLIP: Connecting Images and Language
OpenAI’s CLIP learned image-text relationships.
Training idea:
Image ↔ Caption
The model learns shared embeddings.
This allows:
- Image search
- Zero-shot classification
- Semantic retrieval
Example:
Input image: Dog photo
Prompt: “a golden retriever”
CLIP measures similarity between them.
Why CLIP Was Revolutionary
Traditional vision models needed labeled datasets:
Dog → Label: dog
CLIP learned directly from natural language captions at internet scale.
This made models more flexible and generalizable.
DALL·E: Generating Images from Text
DALL·E transformed text prompts into images:
Example:
“A robot painting in watercolor style”
Output:
- Fully generated artwork
Under the hood:
- Transformer-based generation
- Diffusion techniques in later versions
- Text-image latent spaces
This opened the era of generative visual AI.
GPT-4V: Seeing and Reasoning
GPT-4V introduced visual understanding into conversational AI.
Capabilities:
- Analyze screenshots
- Read charts
- Explain diagrams
- Understand UI layouts
Example:
- User uploads graph
- Model explains trends
This dramatically expanded real-world usability.
The Role of Embeddings
Embeddings are numerical representations of meaning.
Example:
King → [0.2, -1.3, 4.1…]
Queen → [0.1, -1.1, 4.0…]
Semantically similar concepts appear close in vector space.
Applications:
- Search
- Recommendation systems
- Retrieval-Augmented Generation (RAG)
- Semantic matching
Retrieval-Augmented Generation (RAG)
One limitation of LLMs:
They don’t inherently know recent information.
RAG solves this.
Pipeline:
- User Query
- Vector Search
- Relevant Documents
- LLM Response
This enables:
- Company knowledge bots
- Legal assistants
- Documentation chat systems
Simple retrieval example:
from sentence_transformers import SentenceTransformer model = SentenceTransformer('all-MiniLM-L6-v2') embeddings = model.encode([ "AI is transforming healthcare", "Transformers power modern LLMs" ]) print(embeddings.shape)
Fine-Tuning vs Prompt Engineering
Two ways to adapt models:
Prompt Engineering
You guide behavior through instructions.
Example:
You are a cybersecurity expert.
Explain SQL injection simply.
Cheap and flexible.
Fine-Tuning
You retrain model weights on custom datasets.
Benefits:
- Domain specialization
- Better consistency
- Documentation chat systems
Trade-offs:
- Expensive
- Risk of overfitting
- Infrastructure complexity
Quantization: Running LLMs Efficiently
Large models consume enormous memory.
Quantization reduces precision:
32-bit → 16-bit → 8-bit → 4-bit
Benefits:
- Faster inference
- Lower memory usage
- Consumer hardware compatibility
This enables local AI applications on laptops and phones.
Why Context Windows Matter
The context window defines how much information the model can process at once.
Small context:
Forgetful conversations
Large context:
- Long documents
- Large codebases
- Research papers
- Multi-hour conversations
Modern models now support hundreds of thousands or even millions of tokens.
Hallucinations: The Persistent Problem
LLMs often generate plausible but incorrect information.
Why?
Because they optimize for:
Probable next tokens
Not factual truth.
Mitigation strategies:
- RAG
- Tool use
- Verification systems
- Fine-tuning
- Constitutional AI
Hallucinations remain one of AI’s biggest research challenges.
Alignment and Safety
As models become more capable, alignment becomes critical.
Key concerns:
- Harmful outputs
- Bias
- Misinformation
- Jailbreaks
- Autonomous misuse
Techniques include:
- RLHF
- Constitutional AI
- Adversarial testing
- Safety classifiers
Balancing helpfulness with safety is an ongoing challenge.
The Hardware Behind Modern AI
Training modern LLMs requires extraordinary infrastructure.
Common hardware:
- NVIDIA H100 GPUs
- TPU pods
- High-bandwidth interconnects
- Distributed storage systems
A frontier AI cluster may contain:
- Tens of thousands of GPUs
- Megawatts of power usage
- Massive cooling infrastructure
This is why only a few organizations can train frontier-scale models.
The Open Source vs Closed Model Debate
Two major philosophies exist.
Closed Models
Examples:
- GPT-4
- Claude
- Gemini
Advantages:
- Strong safety controls
- Massive resources
- Better optimization
Disadvantages:
- Less transparency
- Vendor lock-in
Open Models
Examples:
- LLaMA ecosystem
- Mistral
- Falcon
Advantages:
- Transparency
- Community innovation
- Local deployment
Disadvantages:
- Easier misuse
- Variable quality
The future likely includes both ecosystems coexisting.
What Makes Modern LLMs Feel Intelligent?
Interestingly, no single component creates intelligence.
It emerges from:
The future likely includes both ecosystems coexisting.
- Massive data
- Transformer architectures
- Scale
- Reinforcement learning
- Optimization techniques
- Human feedback
The interaction of these systems creates surprisingly human-like behavior.
The Future of LLM Architectures
The next generation of AI systems will likely include:
- Better reasoning
- Long-term memory
- Real-time learning
- Autonomous agents
- Multimodal understanding
- Tool orchestration
- Personalized intelligence
Architectures may evolve beyond pure transformers into hybrid systems combining:
- Symbolic reasoning
- Memory modules
- Expert routing
- World models
The field is moving incredibly fast.
Final Thoughts
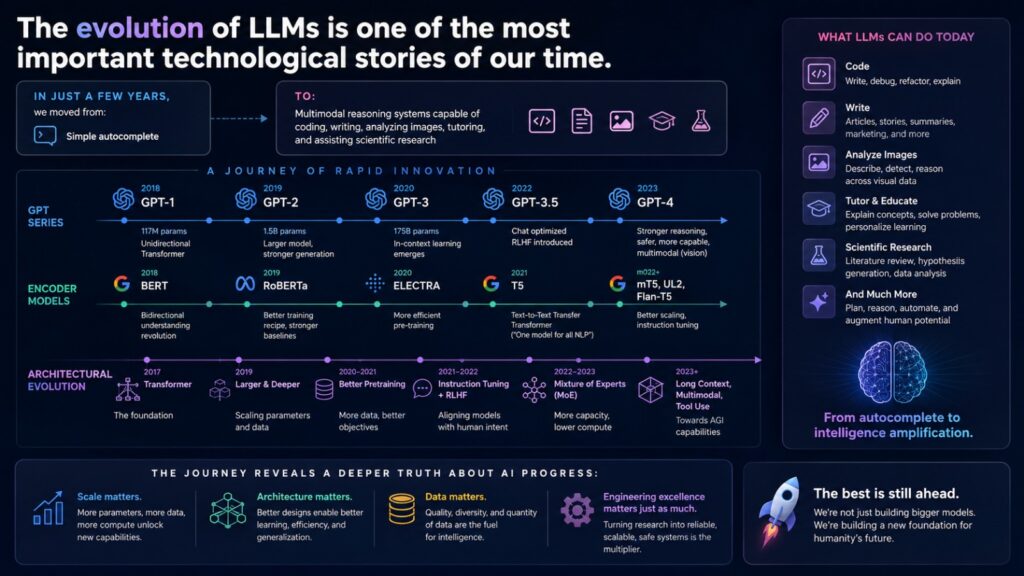
Fig 3. Evolution of LLMs
The evolution of LLMs is one of the most important technological stories of our time.
In just a few years, we moved from:
Simple autocomplete
to:
Multimodal reasoning systems capable of coding, writing,
analyzing images, tutoring, and assisting scientific research
The journey from GPT-1 to GPT-4, from BERT to T5, from dense transformers to Mixture of Experts, reveals a deeper truth about AI progress:
Scale matters. Architecture matters. Data matters. But engineering excellence matters just as much.
Understanding these systems is no longer optional for modern developers, researchers, founders, and technology leaders. LLMs are rapidly becoming foundational infrastructure, much like databases, cloud computing, and the internet itself.
And we are still only at the beginning.
Ready to Build Real-World AI Systems?
Learn how modern AI applications are built using:
Frequently Asked Questions (FAQs)
An LLM is an AI model trained on massive datasets to predict and generate human-like text using transformer architectures.
LLMs are trained using large-scale datasets, tokenization, transformer networks, distributed GPU training, and reinforcement learning techniques like RLHF.
Transformers use self-attention mechanisms to process relationships between words in parallel, enabling better contextual understanding.
MoE activates only specialized parts of a model for each task, reducing compute costs while enabling larger parameter counts.
GPT is decoder-only and optimized for text generation, while BERT is bidirectional and optimized for language understanding tasks.
Retrieval-Augmented Generation combines vector search with LLMs to provide accurate, up-to-date responses from external data sources.