Artificial intelligence has seen many breakthroughs, but very few have had the impact that transformers have had. Today, systems that generate text, translate languages, summarize documents, and even assist in programming are built on top of transformer architectures. Despite this widespread adoption, many people interact with these systems without fully understanding how they work internally.
This blog is designed to give you a deep, intuitive, and practical understanding of transformers. Instead of focusing only on formulas or surface-level explanations, we will explore the reasoning behind each component, how they work together, and why they have become the dominant architecture in modern AI.
1. The Paradigm Shift: From Sequential Processing to Global Understanding
Before transformers, sequence modelling was dominated by architectures like Recurrent Neural Networks and Long Short-Term Memory networks. These models processed text one token at a time, maintaining a hidden state that acted as memory. While this approach was effective for short sequences, it struggled with longer contexts.
The fundamental limitation was that information had to flow through many steps. If an important word appeared early in a sentence, its influence weakened as more words were processed. This made it difficult to capture relationships between distant words. Additionally, because each step depended on the previous one, training could not be parallelized efficiently, which slowed down computation significantly.
Transformers introduced a completely different approach. Instead of processing sequences step by step, they process the entire sequence at once. This allows the model to directly connect any two words, regardless of their position in the sentence. The key mechanism that enables this is attention.
To understand the impact of this shift, consider the sentence, “The animal didn’t cross the road because it was too tired.” The word “it” refers to “animal.” In older models, this relationship had to be preserved through multiple steps of memory.
In transformers, the model directly links “it” to “animal” using attention weights. This ability to model relationships explicitly is what makes transformers so powerful.
2. Encoder and Decoder: The Structural Backbone
Transformers are built using two main components, the encoder and the decoder. Each plays a distinct role in how the model processes and generates information.
The encoder is responsible for understanding the input. It takes raw text and converts it into a contextual representation. Initially, each word is represented as a vector that captures its basic meaning. However, these representations are not aware of context. As the input passes through multiple encoder layers, each word’s representation is refined based on its relationship with other words in the sentence.
For example, in the sentence “The movie was unexpectedly good,” the word “good” gains additional meaning through its interaction with “unexpectedly.” After passing through several encoder layers, the model develops a deeper understanding of sentiment and context.
The decoder, on the other hand, is responsible for generating output. It works sequentially, producing one token at a time. At each step, it considers both the previously generated tokens and, in some architectures, the output of the encoder. This makes the decoder particularly useful for tasks like translation, where it needs to map input sequences to output sequences.
One important feature of the decoder is masking. During training, the model must not have access to future tokens. Masking ensures that the decoder only uses information from past tokens, making the learning process realistic and preventing the model from taking shortcuts.
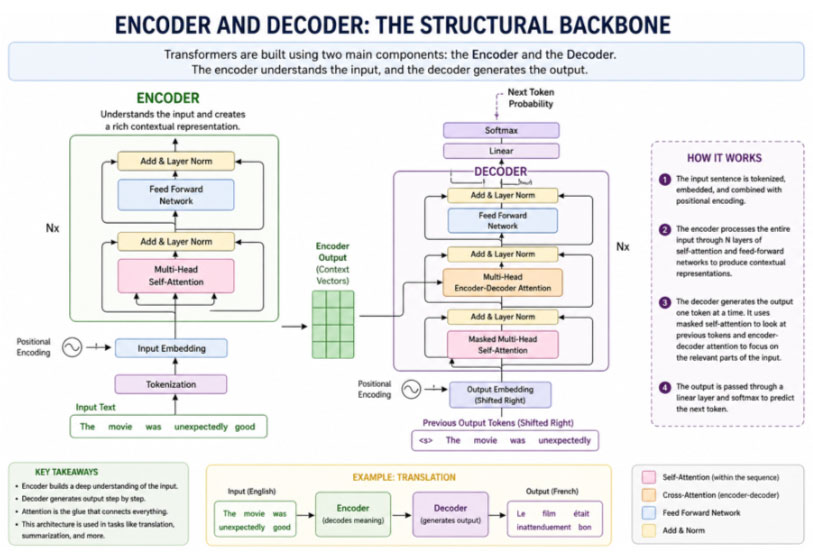
Fig 2.1 Encoder and Decoder : The structural backbone
3. Self-Attention: The Core Mechanism
Self-attention is the heart of the transformer architecture. It allows each token to determine which other tokens are most relevant to it.
When humans read a sentence, they do not treat every word equally. Instead, they focus on words that provide context. Self-attention replicates this behavior mathematically. Each word generates three vectors known as Query, Key, and Value. These vectors are used to compute how much attention each word should pay to others.
The process works by comparing the Query of one token with the Keys of all other tokens. This produces a set of scores that indicate relevance. These scores are then normalized into probabilities, which are used to compute a weighted sum of the Value vectors. The result is a new representation for each token that incorporates information from relevant words.
For example, in the sentence “She gave the book to him because he asked for it,” the word “he” needs to connect to “him.” Self-attention assigns higher weights to relevant words, allowing the model to capture this relationship effectively.
Multi-head attention extends this idea further. Instead of performing a single attention operation, the model performs multiple attention operations in parallel. Each head learns a different type of relationship. Some heads focus on grammar, others on semantic meaning, and others on long-range dependencies. This diversity allows the model to capture complex patterns in language.
4. Positional Encoding: Adding Structure to the Model
One challenge with transformers is that they process all tokens simultaneously, which means they do not inherently understand the order of words. Without positional information, the sentence “I love AI” would be indistinguishable from “AI love I.”
Positional encoding solves this problem by adding information about the position of each token to its embedding. The original transformer used sinusoidal functions to generate these encodings. Each position is assigned a unique pattern, which allows the model to distinguish between different positions.
Over time, researchers have developed alternative approaches. Learned positional embeddings allow the model to learn positional information directly from data. Relative positional encoding focuses on the distance between tokens rather than their absolute positions, which often improves performance in tasks that require understanding long-range relationships.
The key idea is that positional encoding provides structure. It ensures that the model understands not just which words are present, but also how they are arranged. This is essential for capturing grammar and meaning.
5. Residual Connections and Layer Normalization
As transformer models became deeper, training them became more challenging. Two techniques play a crucial role in addressing this challenge: residual connections and layer normalization.
Residual connections allow the model to add the input of a layer directly to its output. This creates a shortcut path for information, ensuring that important signals are not lost as they pass through multiple layers. It also helps gradients flow more effectively during training, which prevents issues like vanishing gradients.
Layer normalization stabilizes the model by ensuring that the values within each layer remain within a consistent range. This reduces fluctuations during training and allows the model to converge more quickly.
Modern transformer architectures often apply normalization before the main transformation, which improves stability and performance, especially in very large models.
6. Feed-Forward Networks: The Computational Backbone
While attention mechanisms handle relationships between tokens, feed-forward networks handle the transformation of those relationships into meaningful representations. Each token is processed independently by a feed-forward network, which consists of two linear transformations with a non-linear activation function in between.
The network typically expands the dimensionality of the input before reducing it back to its original size. This expansion allows the model to learn more complex features. Activation functions such as GELU provide smooth non-linearity, which improves learning.
You can think of attention as gathering relevant information and feed-forward networks as interpreting that information. Both are essential for the model to function effectively.
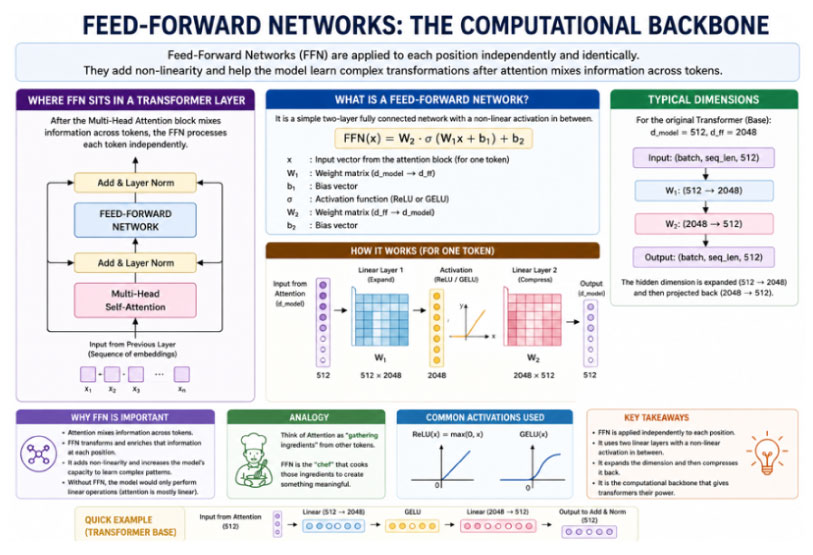
Fig 6.1 Feed-Forward Networks
7. Transformer Variants: Different Architectures for Different Tasks
Transformers are flexible and can be adapted to different tasks by modifying their architecture.
Encoder-only models focus on understanding input text. They are widely used for tasks like sentiment analysis, classification, and question answering. These models process the entire input bidirectionally, which allows them to capture rich context.
Decoder-only models focus on generating text. They predict the next token based on previous tokens, making them suitable for tasks like text generation, chatbots, and code completion. Their autoregressive nature allows them to produce coherent and contextually relevant outputs.
Encoder-decoder models combine both approaches. They are used for tasks that involve transforming one sequence into another, such as translation and summarization. By separating understanding and generation, they achieve high performance in sequence-to-sequence tasks.
8. Efficiency Challenges in Transformers
Despite their success, transformers come with significant computational costs. The attention mechanism requires comparing every token with every other token, which results in quadratic complexity. As the length of the sequence increases, the number of computations grows rapidly.
This makes it difficult to handle very long sequences. It also increases memory usage, which can be a limiting factor in real-world applications. For tasks involving long documents or real-time processing, efficiency becomes a critical concern.
9. Efficiency Improvements
This makes it difficult to handle very long sequences. It also increases memory usage, which can be a limiting factor in real-world applications. For tasks involving long documents or real-time processing, efficiency becomes a critical concern.
Sparse attention reduces the number of interactions by focusing only on relevant tokens. Instead of attending to all tokens, the model attends to a subset, such as nearby words or key positions. This reduces computational cost while maintaining performance.
Linear attention reformulates the attention computation to reduce complexity from quadratic to linear. This makes it possible to process much longer sequences without a significant increase in computation.
Other optimizations improve how attention is implemented on hardware, reducing memory usage and increasing speed. These advancements are essential for scaling transformers to real-world applications.
10. Modern Innovations in Transformer Design
Recent innovations have focused on improving positional encoding and attention mechanisms. Rotary Positional Embeddings encode position through rotations in vector space, which allows the model to generalize better to longer sequences.
Another approach introduces biases based on token distance, encouraging the model to focus more on nearby tokens while still considering long-range relationships. These innovations improve both efficiency and performance, especially in tasks involving long contexts.
11. Real-World Applications
Transformers are used in a wide range of applications. In sentiment analysis, they classify text based on emotional tone. In text generation, they produce coherent and contextually relevant content. In translation, they map sequences from one language to another.
In practice, building a transformer-based system involves several steps, including tokenization, embedding, positional encoding, passing data through transformer layers, and generating outputs. Each step contributes to the overall performance of the model.
12. Final Mental Model
To truly understand transformers, it helps to think of them as a system of interacting components. Attention determines which information is important. Feed-forward networks process that information. Residual connections preserve signals, while normalization stabilizes training. Positional encoding ensures that the structure of the sequence is maintained.
Together, these components form a powerful architecture that can understand and generate complex sequences.
Final Thoughts
Transformers are powerful not because they are complicated, but because they are well-designed. Each component serves a specific purpose, and together they create a system that can model relationships, refine representations, and generate meaningful outputs.
As research continues, transformers are becoming more efficient, more scalable, and more capable. Understanding their core principles is essential for anyone working in modern artificial intelligence.