Introduction: The Intelligence Behind AI
Ever wondered how a machine can look at a picture and instantly say “that’s a cat,” or listen to your voice and convert it into text?
What feels like intelligence is actually the result of learning patterns from data, and neural networks are one of the most powerful tools that make this possible.
At a high level, neural networks are inspired by the human brain. In our brain, neurons receive signals, process them, and pass them forward. Neural networks follow a similar idea, but instead of biological signals, they use numbers, weights, and mathematical functions.
What makes them truly interesting is this:
They don’t rely on hardcoded rules.
They learn the rules themselves.
For example:
- Instead of telling a system “a cat has two ears and whiskers,”
- You show it thousands of cat images, and it learns the pattern on its own.
This shift from rule-based programming → data-driven learning is what powers modern AI.
What is a Neural Network?
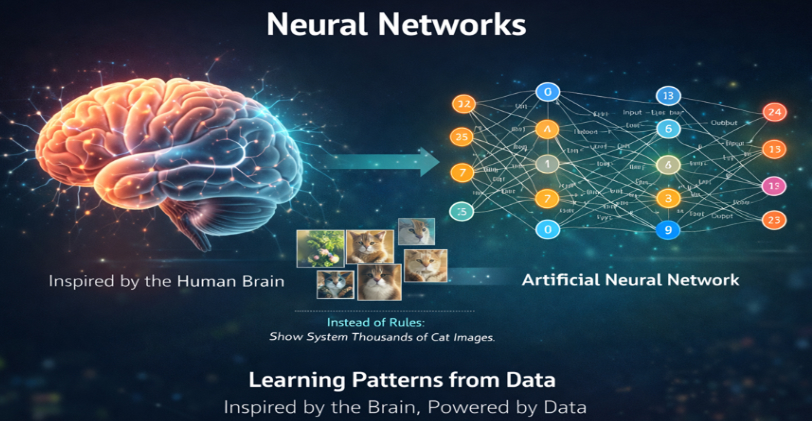
Fig 1.1 Neural Networks – Inspired by the Human Brain
A neural network is essentially a function approximator.
That might sound technical, but here’s a simple way to think about it:
It takes an input, processes it through multiple steps, and produces an output that best matches what it has learned.
Think of it as a Pipeline
Input → Transformation → Output
But unlike a simple program, the “transformation” part is not fixed. It evolves as the model learns.
Breaking It Down Further
Let’s say you’re building a model to predict house prices.
Input
- Size of the house
- Location rating
- Number of rooms
Output
- Predicted price
A neural network learns how these inputs relate to the output.
Initially, it makes random guesses.
But over time, it adjusts itself to produce better predictions.
What Happens Inside?
Each layer in a neural network performs two main steps:
-
Weighted Sum
It combines inputs using weights (importance values) -
Activation Function
It decides how much of that information should pass forward
This process repeats layer by layer.
Why Multiple Layers?
Each layer learns a different level of abstraction.
Let’s take an example of image recognition:
- First layer: detects edges
- Second layer: detects shapes
- Third layer: detects objects
- Final layer: classifies the image
So instead of manually designing features, the network builds its own understanding step by step.
Intuition with a Real-Life Analogy
Think of a neural network like a team making a decision.
- The first group looks at raw data and extracts basic insights
- The next group refines those insights
- The final group makes the decision
Each group adds more clarity.
A Simple End-to-End Example
Let’s say you want to predict whether a student will pass an exam.
Input Features
- Hours studied
- Attendance
- Sleep quality
What the Network Does
- Assigns importance to each feature
- Combines them
- Passes them through transformations
- Produces a probability
Output
- 0.85 → likely to pass
- 0.20 → likely to fail
Over time, the network improves by comparing its predictions with actual results and adjusting itself.
The Foundation: Perceptrons
The perceptron is the simplest form of a neural network. It acts like a single decision-making unit.
It takes inputs, assigns importance to them using weights, adds a bias, and produces an output.
y = f(∑i=1n wixi + b)
Breaking It Down
- Inputs represent features
- Weights determine importance
- Bias shifts the decision boundary
- Activation function decides the final output
Example
Imagine predicting whether a student will pass an exam:
- Hours studied
- Attendance
- Sleep quality
Each factor contributes differently. The perceptron combines them to make a prediction.
Visual Understanding of a Perceptron
You can visualize it as inputs flowing into a node, getting combined, and producing a result.
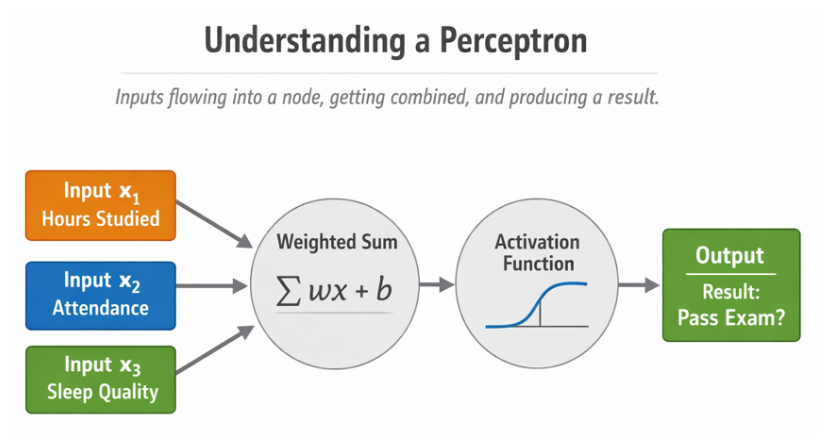
Fig 1.2 Understanding a perceptro
Why Perceptrons Were Not Enough
Perceptrons can only solve problems where data can be separated using a straight line.
This limits their ability to handle real-world complexity.
A classic example is the XOR problem, where no straight line can separate the outputs correctly.
This limitation led to a major shift towards deeper architectures.
Enter Multi-Layer Neural Networks
To overcome the limitations of a single perceptron, multiple layers were introduced.
Structure
- Input layer
- One or more hidden layers
- Output layer
Why Layers Matter
Each layer extracts more meaningful features.
For example, in image recognition:
- First layer detects edges
- Next layer identifies shapes
- Final layers recognize objects
This layered learning is what makes neural networks powerful.
Activation Functions: Enabling Complexity
If neural networks only performed linear operations, they would behave like a single-layer model regardless of depth.
Activation functions solve this by introducing non-linearity.
Sigmoid Function
σ(x) = 1 / (1 + e-x)
- Output between 0 and 1
- Useful for probability-based predictions
ReLU Function
f(x) = max(0, x)
- Simple and efficient
- Widely used in deep learning
Tanh Function
- Output between -1 and 1
- Better centered compared to sigmoid
Loss Functions: Measuring Performance
A model improves by understanding how wrong it is. That measure of error is called the loss.
Mean Squared Error
MSE = (1/n) ∑i=1n (yi - ŷi)2
Commonly used in regression tasks.
Cross-Entropy Loss
L = -∑ y log(ŷ)
Used in classification problems where outputs are probabilities.
Optimization: Learning Through Adjustment
Once the loss is calculated, the model adjusts its weights to reduce that loss.
Gradient Descent
w = w - η (∂L / ∂w)
- Learning rate controls step size
- Gradients indicate direction of improvement
Intuition
Imagine trying to reach the lowest point in a valley while blindfolded. You rely only on the slope beneath your feet to decide where to step next.
That is how gradient descent works.
Forward Propagation: From Input to Output
Forward propagation is the process of generating predictions.
Steps
- Input enters the network
- Each layer applies transformations
- Final output is produced
Backward Propagation: Learning from Mistakes
After making a prediction, the model calculates how far off it was.
Backward propagation distributes this error back through the network.
Core Idea
- Compute loss
- Calculate gradients
- Update weights
This allows every weight to adjust based on its contribution to the error.
Putting Everything Together
Training a neural network follows a loop:
- Initialize weights
- Perform forward propagation
- Compute loss
- Perform backward propagation
- Update weights
- Repeat
Over time, the model becomes better at predictions.
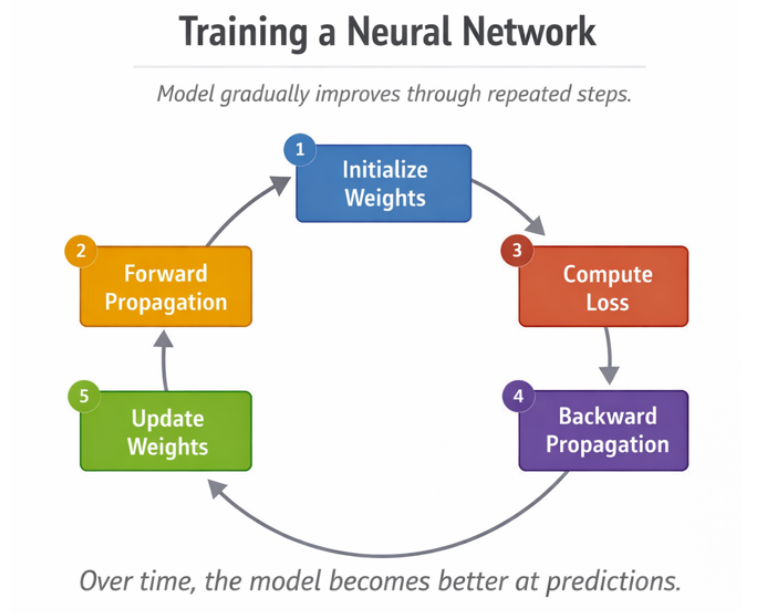
Fig 1.3 Training a Neural Network
Real-World Example: Predicting House Prices
Consider a system that predicts house prices.
Inputs
- Size of the house
- Location rating
- Number of rooms
Learning Process
The network learns relationships between these features and price using historical data.
Output
A predicted house price that improves with training.
Why Neural Networks Are Powerful
- They learn patterns automatically
- They improve with more data
- They handle complex relationships
This is why they are widely used in areas like computer vision, natural language processing, and recommendation systems.
Challenges to Be Aware Of
Neural networks are powerful but not perfect.
Some common challenges include:
- Overfitting
- Vanishing gradients
- High computational requirements
These are addressed using techniques like regularization, normalization, and improved architectures.
Final Thoughts
Neural networks often appear intimidating at first. The terminology, the layers, the math, the diagrams, it can feel like there is a lot happening under the hood. But if you strip everything down to its essence, the entire system revolves around one beautifully simple idea:
Learn from mistakes and improve over time.
At every step, a neural network makes a prediction. That prediction is compared with the actual answer, and the difference between the two becomes the error. This error is not just a number, it is a signal. It tells the network how far off it is and in which direction it needs to improve.
Instead of rewriting rules manually, the network adjusts its internal parameters, the weights, to reduce that error. Over multiple iterations, these small adjustments accumulate, and the model gradually becomes better at capturing patterns in data.
Neural networks are a perfect example of how simple ideas, when applied repeatedly and at scale, can lead to extraordinary results.
If you can internalize this one concept
“Adjust weights based on error”
You already understand the heart of modern AI.
Everything else is just a deeper refinement of that idea.
If you want to go beyond theory and actually build intelligent systems, the next step is practice.
Work on projects, experiment with models, and explore real datasets.
For more structured learning and hands-on guidance, check out:
https://codekerdos.in/