Artificial Intelligence has evolved through a series of profound conceptual shifts rather than steady, incremental improvements. Each phase redefined how machines interpret data, learn patterns, and interact with the world. What began as rigid, rule-driven systems has transformed into highly adaptive and generative models such as GPT, Claude, and Gemini.
Understanding this journey is essential not just for researchers and engineers, but for anyone engaging with modern AI systems. It reveals how we moved from explicitly programming intelligence to building systems that learn, reason, and even create.
AI Evolution Timeline
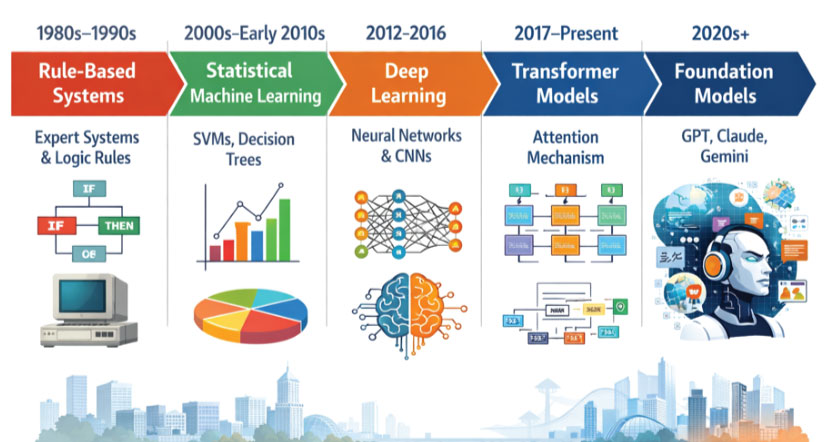
Fig 1.1 The AI Evolution Timeline
The age of rule-based intelligence
The earliest attempts at artificial intelligence were grounded in symbolic reasoning. In this phase, intelligence was seen as a set of logical rules that could be encoded into a machine. Engineers and domain experts worked together to translate human knowledge into structured decision trees and conditional statements.
A simple rule-based system might look like this.
If temperature > 38 AND cough = true THEN diagnosis = flu
These systems were widely deployed in domains where decision-making could be formalized, such as medical diagnostics, tax systems, and early chatbots. They offered a level of transparency that is still valued today. Every output could be traced back to a specific rule, making them interpretable and easy to debug.
However, the limitations quickly became apparent. Real-world scenarios are rarely clean or predictable. Human language is ambiguous, environments are dynamic, and edge cases are abundant. As systems grew more complex, maintaining and updating rule sets became increasingly difficult. Adding a new rule could unintentionally conflict with existing ones, leading to unpredictable behaviour.
Moreover, these systems lacked the ability to learn. Every improvement required manual intervention. They could not adapt to new patterns or unseen data, which severely restricted their scalability.
The shift to statistical machine learning
The explosion of digital data in the late 20th and early 21st centuries opened the door to a new approach. Instead of explicitly defining rules, researchers began building systems that could learn patterns directly from data. This marked the rise of statistical machine learning.
In this paradigm, models are trained on datasets to identify relationships between inputs and outputs. Rather than asking “What rules should the system follow,” the question became “What patterns exist in the data?”
Algorithms such as linear regression, decision trees, support vector machines, and naive Bayes classifiers became foundational tools. These models relied on mathematical principles to estimate probabilities and make predictions.
Consider the problem of spam detection. Instead of writing rules like “emails containing the word ‘free’ are spam,” a machine learning model analyzes thousands of emails and learns the likelihood of certain words appearing in spam versus legitimate messages. The result is a system that can generalize beyond explicitly defined rules.
Example implementation
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
texts = [“Win money now”, “Hello friend”, “Free offer available”]
labels = [1, 0, 1]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
model = LogisticRegression()
model.fit(X, labels)
print(model.predict(vectorizer.transform([“Free money”])))
This shift brought significant advantages. Systems became more flexible and could improve as more data became available. They were no longer limited to predefined scenarios and could adapt to new inputs.
However, statistical machine learning introduced its own challenges. One of the most significant was feature engineering. Engineers had to carefully design input features that captured relevant information from raw data. For example, in text classification, deciding whether to use word counts, n-grams, or TF-IDF representations required domain expertise.
Additionally, these models struggled with unstructured data such as images, audio, and natural language. While they performed well on structured datasets, their ability to handle complexity was limited.
The deep learning breakthrough
Fig 1.2 Deep Learning Breakthrough
Deep learning brought a new level of performance and capability, but it was not without limitations. Training deep neural networks required large amounts of data and computational power. This made them resource-intensive and inaccessible to smaller organizations.
Sequential models like RNNs also faced difficulties in capturing long-range dependencies in text. Information from earlier parts of a sequence could be lost as the model processed later elements. This limitation became particularly evident in natural language processing tasks, where context is critical.
The Transformer Revolution
A fundamental breakthrough occurred with the introduction of the transformer architecture by Google Brain. This innovation addressed many of the limitations of previous models and laid the foundation for modern AI systems.
The key idea behind transformers is the attention mechanism. Instead of processing data sequentially, transformers analyze entire sequences simultaneously and learn which parts of the input are most relevant to each other.
This shift from sequential to parallel processing brought several advantages. Models could be trained more efficiently, making it possible to scale them to unprecedented sizes. More importantly, they gained a deeper understanding of context. For example, in the sentence “The bank by the river was calm,” the word “bank” can have multiple meanings. Transformers use attention to determine that “river” provides context, helping the model interpret the correct meaning.
Visual representation of transformers
Transformers and the Attention Mechanism
Fig 1.3 Transformer Architecture
Transformers marked a turning point in natural language processing and beyond. They enabled the development of models that could handle long sequences, understand context more effectively, and scale with increasing data and compute.
The Emergence of Foundation Models
Building on the transformer architecture, researchers began training models on massive datasets containing diverse information from across the internet. These models, known as foundation models, represent a significant shift in how AI systems are developed and deployed.
Instead of training a separate model for each task, a single foundation model can be adapted to perform many tasks. This is achieved through fine-tuning or prompting, where the model is guided to produce desired outputs based on input instructions.
This approach has fundamentally changed the way developers interact with AI. Tasks that once required complex pipelines and specialized models can now be performed using a single, general-purpose system.
Foundation models are also increasingly multimodal. They can process and generate not just text, but also images, audio, and video. This opens up new possibilities for applications ranging from content creation to scientific research.
The Current AI Landscape
Today’s AI ecosystem is shaped by a small number of powerful model families developed by leading organizations.
OpenAI has developed the GPT series, which excels in natural language understanding, content generation, and code synthesis. These models are widely used in chatbots, productivity tools, and developer assistants.
Anthropic focuses on building AI systems that are aligned with human values. Their Claude models are designed to be reliable, interpretable, and capable of handling long-context interactions.
Google DeepMind continues to push the boundaries with Gemini, which integrates multimodal capabilities and leverages deep research expertise.
These models are not just tools; they are platforms. They enable a wide range of applications, from automated customer support to creative writing, from coding assistance to scientific discovery.
Where the Paradigm is Heading
The evolution of AI is far from complete. Several emerging trends suggest where the next paradigm shift may occur.
One significant direction is the development of AI agents. These systems go beyond generating responses to actively planning and executing tasks. They can interact with external tools, make decisions, and adapt to changing environments.
Another important trend is multimodal intelligence. Future models will seamlessly integrate text, images, audio, and video, enabling richer and more natural interactions.
Personalization is also becoming a key focus. AI systems are increasingly tailored to individual users, learning preferences and adapting behavior accordingly.
At the same time, there is a growing emphasis on efficiency. Researchers are working on smaller, more efficient models that can run on edge devices, making AI more accessible and sustainable.
Closing Perspective
Fig 1.4 Current AI Landscape
The history of AI is a story of abstraction and capability. Each paradigm shift has moved us further away from rigid, human-defined logic and closer to systems that can learn, adapt, and reason.
What began as a collection of rules has evolved into a new form of computational intelligence. Today’s models can generate ideas, solve complex problems, and collaborate with humans in ways that were once unimaginable.
As we look to the future, the focus will not only be on making machines more intelligent, but also on ensuring that this intelligence is aligned, ethical, and beneficial.
The journey from rules to reasoning machines is not just a technological evolution. It is a transformation in how we understand intelligence itself.
Closing Perspective
Explore amazing blogs and enrol in practical courses here:
https://codekerdos.in/