It sounds counterintuitive, but it’s true.
Before an AI model can generate human-like responses, summarize documents, or translate languages, it faces a surprisingly difficult task: understanding raw text. And not in the way humans do. For machines, language is not inherently meaningful, it’s just a sequence of symbols, patterns, and noise.
This is where the real story of Natural Language Processing (NLP) begins, not with intelligence, but with transformation.
This blog dives deep into that transformation: how raw text is broken down, cleaned, structured, and eventually turned into mathematical representations that machines can learn from. Along the way, we’ll explore how techniques evolved from rigid rule-based systems to flexible neural architectures, and why representation, not just modelling, is the true backbone of modern AI.
If you’re looking to start your journey in Generative AI and NLP, understanding this foundation is essential.
From Chaos to Structure: Why Text Preprocessing Matters
Imagine feeding the following sentence to a machine:
“OMG!!! This movie is soooo goooood 🔥 #MustWatch”
To a human, this clearly conveys excitement and positive sentiment.
To a machine, however, it looks like a chaotic mix of:
- Repeated characters
- Emojis
- Slang
- Hashtags
- Punctuation noise
If we don’t process this text properly, even the most advanced model will struggle.
Text preprocessing is not just a preliminary step, it is the foundation of everything that follows.
Tokenization: Teaching Machines to Read
Tokenization is the process of splitting text into smaller units called tokens. These tokens form the building blocks for all NLP tasks.
But here’s where it gets interesting: there are multiple ways to tokenize text, and each comes with trade-offs.
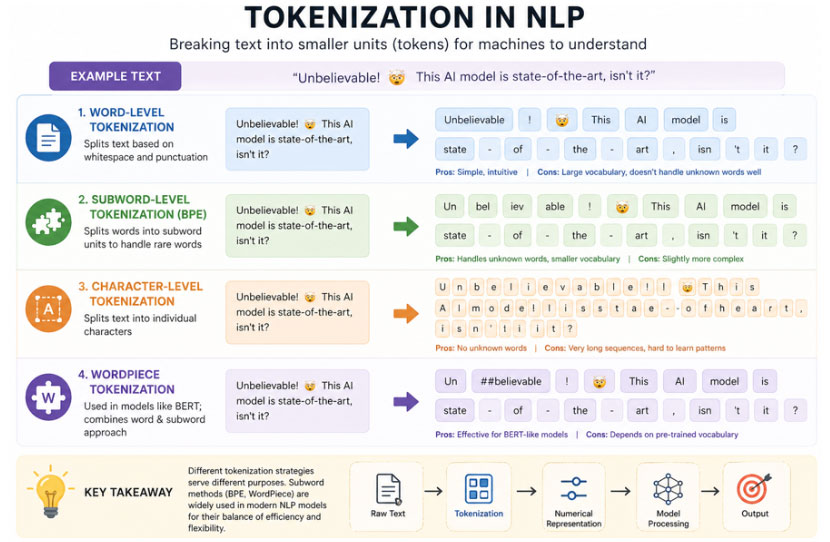
Fig 1.1 Tokenization in NLP
Word-Level Tokenization: The Intuitive Start
At first glance, splitting text into words seems natural:
“I love AI” → [“I”, “love”, “AI”]
This approach works well for simple tasks and aligns with human understanding. However, it quickly runs into limitations:
- Vocabulary size grows rapidly
- Rare or unseen words become problematic
- Morphological variations (run, running, ran) are treated as separate entities
This leads to inefficiencies and poor generalization.
Character-Level Tokenization: Going Deeper
“I love AI” → [‘I’, ‘ ‘, ‘l’, ‘o’, ‘v’, ‘e’, …]
This approach eliminates the problem of unknown words entirely. Every possible input can be represented.
However, it introduces new challenges:
- Sequences become significantly longer
- Models need to learn meaning from very small units
- Training becomes computationally expensive
While powerful, character-level models often require more data and deeper architectures.
Subword Tokenization: The Sweet Spot
Modern NLP systems rely heavily on subword tokenization, which strikes a balance between word-level and character-level approaches.
Example:
“unbelievable” → [“un”, “believ”, “able”]
Popular algorithms include:
- Byte Pair Encoding (BPE)
- WordPiece (used in models like BERT)
- SentencePiece
Why subword tokenization works so well:
- Handles rare and unseen words effectively
- Reduces vocabulary size
- Preserves meaningful linguistic patterns
This is why most transformer-based models use subword tokenization-it offers both flexibility and efficiency.
Cleaning the Data: Text Normalisation
Once tokenized, text still contains inconsistencies that can confuse models. Text normalization aims to standardize input.
Common Techniques
Lowercasing
Reduces vocabulary size:
“AI” and “ai” → “ai”
Removing Punctuation
“Hello!!!” → “Hello”
Stopword Removal
“The cat is on the mat” → “cat mat”
Stemming
Reduces words to root forms:
“running”, “runs” → “run”
Lemmatization
More linguistically accurate:
“better” → “good”
The Trade-Off
While normalization improves consistency, it can also remove important context.
Example:
“I am not happy” → “happy”
The meaning is completely reversed.
This is why modern neural approaches often minimize aggressive preprocessing-models can learn patterns directly from raw data.
Beyond English: Multilingual Text and Unicode
Language diversity introduces another layer of complexity.
Consider:
- Hindi: नमस्ते
- Chinese: 你好
- Arabic: مرحبا
Each language has its own script, structure, and encoding challenges.
Unicode: The Universal Standard
Unicode provides a consistent way to represent characters across languages.
Example:
‘é’ → U+00E9
Without Unicode, global NLP systems would be fragmented and inconsistent.
Challenges in Multilingual NLP
- Some languages lack clear word boundaries (e.g., Chinese)
- Code-mixing is common:
“Kal meeting hai bro”
- Grammar and syntax vary significantly
Modern Solutions
- Multilingual transformer models
- Shared embedding spaces
- Language-agnostic tokenization
These advancements allow a single model to understand multiple languages effectively.
Turning Words into Numbers: Word Embeddings
Once text is cleaned and tokenized, it must be converted into a numerical format.
Machines don’t understand words, they understand vectors.
One-Hot Encoding: The Beginning
Each word is represented as a vector with a single “1”:
“cat” → [0, 0, 1, 0, 0]
While simple, this approach has major drawbacks:
- No notion of similarity
- Sparse and inefficient
- High dimensionality
Word2Vec: Learning Meaning from Context
Word2Vec introduced the idea that meaning comes from context.
Words that appear in similar contexts have similar representations.
Example:
“king” – “man” + “woman” ≈ “queen”
This demonstrated that embeddings can capture semantic relationships.
GloVe: Combining Local and Global Context
GloVe (Global Vectors) uses co-occurrence statistics across the entire corpus.
It captures:
- Local relationships (like Word2Vec)
- Global statistical structure
This results in richer representations.
FastText: Understanding Subwords
FastText improves embeddings by considering character-level information.
Instead of treating words as atomic units, it breaks them into n-grams.
This allows:
- Better handling of rare words and Improved performance

Fig 1.2 Word Embeddings in NLP
Static vs Contextual Embeddings: A Paradigm Shift
Traditional embeddings assign a single vector per word.
Static Embeddings:
“bank” → same vector always
Problem:
- Cannot distinguish meanings based on context
Contextual Embeddings
Modern models generate embeddings dynamically.
“I went to the bank” → financial meaning
“The river bank is wide” → geographical meaning
Models like transformers capture context by analyzing surrounding words.
Why This Changed Everything
Contextual embeddings enable:
- Better understanding of ambiguity
- Improved translation accuracy
- More natural interactions
This shift is one of the biggest breakthroughs in NLP.
Measuring Meaning: Semantic Similarity
Once words are represented as vectors, we can measure how similar they are.
Cosine Similarity
Measures the angle between two vectors.
- Closer to 1 → more similar
- Closer to 0 → unrelated
Applications
- Search engines
- Recommendation systems
- Chatbots
- Document clustering
Analogy Tasks
Embeddings can solve relationships:
Paris : France :: Tokyo : Japan
This shows that models capture structure in language, not just words.
Traditional NLP: The Rule-Based Era
Before deep learning, NLP relied on handcrafted rules.
Rule-Based Systems
Examples:
- Grammar rules
- Pattern matching
Strengths:
- Interpretable
- Precise for specific tasks
Weaknesses:
- Difficult to scale
- Cannot handle ambiguity well
Feature Engineering
Engineers manually design features:
- Word counts
- N-grams
- Part-of-speech tags
Example:
“This movie is great” → positive sentiment
Features might include:
- Presence of “great”
- Sentence structure
Limitations:
- Time-consuming
- Domain-dependent
- Poor generalization
Neural NLP: Learning Everything from Data
Modern NLP replaces manual design with learning.
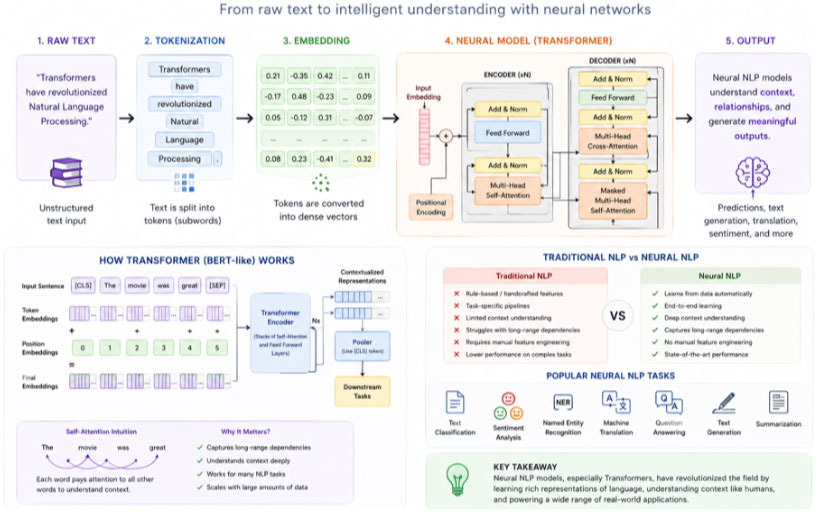
Fig 1.3 Neural NLP
End-to-End Learning
Instead of:
Text → Features → Model → Output
We now have:
Text → Model → Output
The model learns:
- Features
- Patterns
- Representations
Advantages:
- Scales with data
- Adapts to new domains
- Achieves state-of-the-art performance
Challenges:
- Requires large datasets
- Computationally intensive
- Less interpretable
Evaluating NLP Models: Beyond Accuracy
Evaluation is critical but complex.
Accuracy:
Useful for classification.
Precision:
Measures correctness of positive predictions.
Recall:
Measures completeness.
F1 Score:
Balances precision and recall.
Task-Specific Metrics
BLEU:
Used for translation.
BLEU:
Used for summarization.
Perplexity:
Measures language model uncertainty.
The Bigger Insight
Metrics don’t always reflect real-world performance.
A chatbot might score high on benchmarks but still feel unnatural.
Human evaluation remains essential.
The Complete NLP Pipeline
Let’s connect everything:
- Raw Text
- Tokenization
- Normalization
- Embedding
- Model Processing
- Output
Each step plays a crucial role.
A mistake early in the pipeline can cascade into poor results later.
Why Representation is Everything
At its core, NLP is about representation.
The way we encode language determines:
- What patterns can be learned
- How meaning is captured
- How well models perform
Better representation leads to better intelligence.
The Future of NLP
The field continues to evolve rapidly.
Key Trends
Multimodal Models:
Combining text, images, and audio.
Unified Architectures
One model handling multiple tasks.
Low-Resource Learning
Performing well with limited data.
Longer Context Understanding
Handling entire documents instead of short snippets.
Final Reflection
When you interact with AI, it feels natural. Almost human.
But underneath, there is a complex pipeline:
- Text is broken down
- Cleaned and normalized
- Converted into vectors
- Processed through layers of computation
What feels like understanding is actually mathematical pattern recognition at scale.
And it all begins with how we preprocess and represent text.
Closing Thought
If you’re building AI systems, remember:
- Preprocessing is not a trivial step; it defines your model’s foundation
- Tokenization choices affect performance more than you think
- Embeddings determine how meaning is captured
- Representation shapes intelligence
Because in the end AI doesn’t understand language the way humans do.
It understands the representation of language we give it.
If you’re ready to go beyond theory and start your journey in Generative AI today, now is the perfect time to begin.