Artificial Intelligence has entered a transformative era. Large Language Models (LLMs) such as GPT, Llama, Gemini, Claude, and Mistral are no longer just experimental systems confined to research labs. They are powering search engines, coding assistants, scientific discovery, autonomous agents, and enterprise automation.
But behind the smooth conversational interfaces lies an enormous engineering effort involving distributed systems, petabytes of datasets, sophisticated training objectives, and scaling methodologies that push modern computing infrastructure to its limits.
This article explores the foundations of modern AI training methodologies and explains how model size influences intelligence, reasoning, and emergent abilities. Along the way, we’ll use practical examples and code snippets to make these advanced concepts easier to understand.
1. Understanding Modern AI Training Pipelines
Training a large language model involves three major stages:
- 1. Data Collection & Preprocessing
- 2. Pre-training
- 3. Fine-tuning & Alignment

Fig 1. Understanding Modern AI Training Pipelines
A simplified pipeline looks like this:
- Raw Internet Data
- Filtering & Cleaning
- Tokenization
- Pre-training
- Fine-tuning
- RLHF / Alignment
- Deployment
Each stage introduces engineering challenges involving scalability, efficiency, and quality control.
2. Pre-Training Objectives and Datasets
Pre-training is the phase where models learn language patterns, reasoning structures, and world knowledge from massive datasets.
2.1 The Core Objective: Predict the Next Token
The most common objective used in autoregressive language models is:
This means the model learns to predict the next word (or token) given previous tokens.
For example:
Input: “The capital of France is”
Target: “Paris”
During training, billions of such predictions occur repeatedly.
2.2 Example: A Simple Pre-training Loop in PyTorch
import torch import torch.nn as nn # Sample tokenized input inputs = torch.tensor([[1, 5, 8, 10]]) targets = torch.tensor([[5, 8, 10, 15]]) # Simple embedding + linear model model = nn.Sequential( nn.Embedding(1000, 64), nn.Flatten(), nn.Linear(64 * 4, 1000) ) criterion = nn.CrossEntropyLoss() output = model(inputs) loss = criterion(output, targets[:, -1]) loss.backward() print("Training Loss:", loss.item())
This tiny example captures the essence of language model training.
3. Types of Pre-Training Objectives
Modern AI systems use different objectives depending on the architecture and use case.
3.1 Causal Language Modeling (CLM)
Used in GPT-style models.
The model predicts future tokens only.
Example:
“The sky is blue because”
The model predicts the next token step by step.
Advantages:
- Excellent for text generation
- Strong conversational capabilities
- Good few-shot learning behavior
3.2 Masked Language Modeling (MLM)
Example:
“The sky is [MASK]”
The model predicts the missing word.
Advantages:
- Strong contextual understanding
- Better for classification tasks
- Excellent embeddings
3.3 Sequence-to-Sequence Objectives
Used in T5 and encoder-decoder architectures.
Example:
Translate English to French:
“The cat is sleeping”
Output:
“Le chat dort”
This is useful for:
- Translation
- Summarization
- Structured generation
4. Training Datasets: The Fuel of Intelligence
Data quality is often more important than model size.
Modern LLMs are trained on:
- Web pages
- GitHub repositories
- Scientific papers
- Books
- Forums
- Wikipedia
- Stack Overflow
- Instruction datasets
4.1 Common Datasets
Dataset | Purpose |
|---|---|
Common Crawl | Web-scale text |
The Pile | Diverse NLP corpus |
C4 | Cleaned web text |
GitHub Code | Code generation |
Wikipedia | Factual knowledge |
ArXiv Papers | Scientific reasoning |
4.2 Why Data Quality Matters
A 7B parameter model trained on high-quality curated data can outperform a poorly trained 70B model.
Garbage data leads to:
- Hallucinations
- Bias
- Toxic outputs
- Weak reasoning
5. Data Preprocessing and Filtering
Raw internet data is messy.
Models cannot simply consume unfiltered web pages.
Preprocessing involves:
- Deduplication
- Toxicity filtering
- Language detection
- HTML removal
- Token normalization
- Quality scoring
5.1 Example: Text Cleaning Pipeline
import re def clean_text(text): text = re.sub(r'<.*?>', '', text) # Remove HTML text = re.sub(r'http\S+', '', text) # Remove URLs text = re.sub(r'\s+', ' ', text) # Normalize spaces return text.strip() sample = "<p>Hello world!</p> Visit https://example.com" print(clean_text(sample))
Output:
Hello world! Visit
5.2 Deduplication
Duplicate data causes memorization problems.
For example:
- Thousands of copies of the same article
- Repeated GitHub repositories
- Mirror websites
Common techniques:
- MinHash
- Locality-sensitive hashing
- Embedding similarity
5.3 Toxicity Filtering
Modern systems remove:
- Hate speech
- Malware code
- Explicit content
- Dangerous instructions
Tools used:
- Perspective API
- Custom classifiers
- Heuristic filters
6. Scaling Laws and Computational Requirements
One of the most important discoveries in AI research is that model performance scales predictably with:
- More parameters
- More data
- More compute
These are called scaling laws.
6.1 The Scaling Law Concept
Performance improves approximately as a power law:
Tools used:
- LLL = loss
- NNN = number of parameters
- α\alphaα = scaling coefficient
This means larger models generally become more capable.
7. Computational Requirements of LLM Training
Training frontier models requires enormous infrastructure.
Model Size | GPUs Required | Approx Training Cost |
|---|---|---|
7B | 64–128 GPUs | Hundreds of thousands USD |
70B | 512–2048 GPUs | Millions USD |
500B+ | Tens of thousands GPUs | Hundreds of millions USD |
7.1 FLOPs Estimation
Training cost is measured in floating-point operations (FLOPs).
Approximation:
Where:
- NNN = parameters
- DDD = number of tokens
For a 70B model trained on 2 trillion tokens:
FLOPs ≈ 6 × 70B × 2T
This becomes astronomically large.
8. Distributed Training Strategies
A single GPU cannot train large models.
Modern AI relies on distributed training.
8.1 Data Parallelism
Each GPU gets:
- Same model
- Different data batches
GPU 1 → Batch A
GPU 2 → Batch B
GPU 3 → Batch C
Gradients are synchronized afterward.
Example with PyTorch Distributed
import torch.distributed as dist dist.init_process_group("nccl") tensor = torch.tensor([1.0]).cuda() dist.all_reduce(tensor) print(tensor)
This synchronizes gradients across GPUs.
8.2 Model Parallelism
The model itself is split across GPUs.
Example:
GPU 1 → Layers 1–12
GPU 2 → Layers 13–24
GPU 3 → Layers 25–36
Useful when models exceed GPU memory.
8.3 Tensor Parallelism
Individual tensor operations are distributed.
Example:
- Matrix multiplication divided across GPUs
Used heavily in:
- Megatron-LM
- DeepSpeed
- NVIDIA NeMo
8.4 Pipeline Parallelism
Different GPUs process different pipeline stages simultaneously.
Stage 1 → Embedding
Stage 2 → Attention
Stage 3 → Feed Forward
This improves throughput.
9. Memory Optimization Techniques
Training large models introduces severe memory bottlenecks.
Solutions include:
- Gradient checkpointing
- Mixed precision training
- Quantization
- Optimizer sharding
9.1 Mixed Precision Training
Uses FP16 or BF16 instead of FP32.
Benefits:
- Faster computation
- Reduced memory usage
- Better throughput
Example:
from torch.cuda.amp import autocast with autocast(): output = model(input)
10. Parameter Scaling and Emergent Abilities
As models grow larger, unexpected abilities emerge.
These are called emergent abilities.
10.1 What Are Emergent Abilities?
Capabilities that appear suddenly after crossing certain scale thresholds.
Example:
- Multi-step reasoning
- Code generation
- Translation
- Chain-of-thought reasoning
- Tool usage
Small models may completely fail these tasks.
Large models suddenly succeed.
10.2 Example of Emergence
A small model:
Question:
If John has 3 apples and buys 2 more, how many?
Answer:
7
A larger model:
3 + 2 = 5
Reasoning quality improves dramatically with scale.
11. Why Scaling Creates Intelligence
- Better internal representations
- Richer semantic relationships
- Improved abstraction
- More robust contextual understanding
This happens because transformers learn compressed statistical representations of the world.
Larger models develop:
12. Few-Shot vs Zero-Shot Learning
Modern LLMs can solve tasks without explicit retraining.
This is revolutionary.
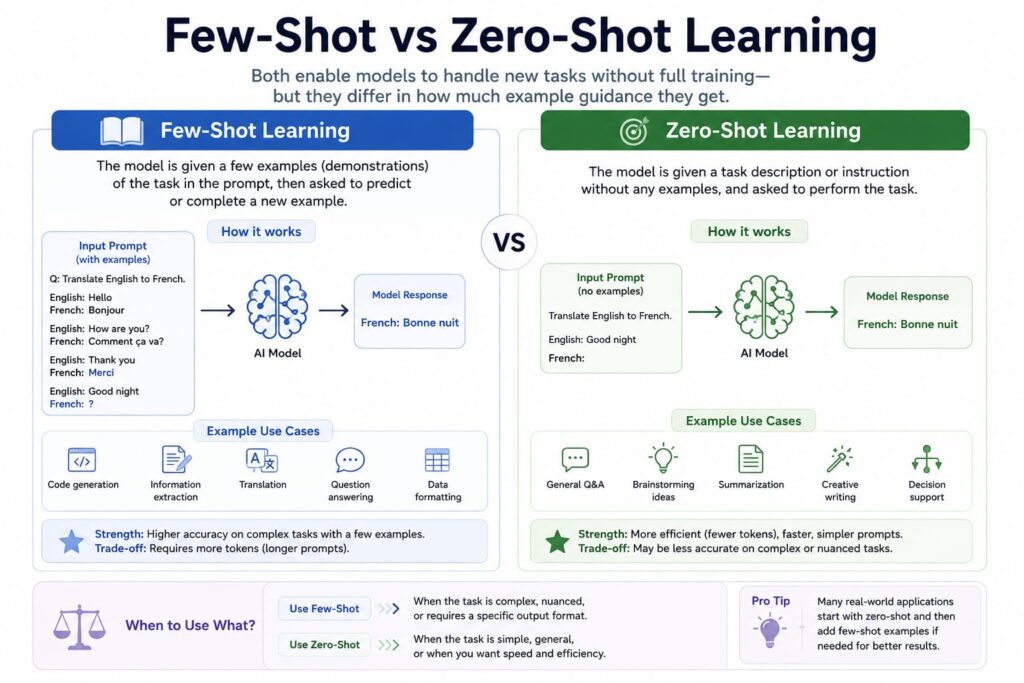
Fig 2. Few-Shot vs Zero-Shot Learning
12.1 Zero-Shot Learning
The model receives instructions only.
A small model:
Translate to French:
“I love programming”
No examples provided.
12.2 Few-Shot Learning
The prompt contains demonstrations.
Example:
English: Hello
French: Bonjour
English: Thank you
French: Merci
English: Good morning
French:The model infers the pattern.
12.3 Why Few-Shot Works
Transformers learn:
- Task structures
- Statistical patterns
- Language mappings
The prompt itself becomes temporary training context.
13. In-Context Learning Mechanisms
One of the most fascinating abilities of transformers is in-context learning.
The model appears to “learn” during inference without updating weights.
13.1 How In-Context Learning Works
The transformer uses attention mechanisms to identify patterns inside the prompt.
For example:
Input → Examples → New Task
The model internally maps:
- Inputs to outputs
- Syntax patterns
- Reasoning trajectories
13.2 Attention Mechanism
The transformer’s core operation:
This enables:
- Long-range dependencies
- Pattern matching
- Contextual reasoning
14. Practical Example of In-Context Learning
Prompt:
Input: cat → animal
Input: rose → flower
Input: eagle →
Output:
bird
The model infers the classification pattern from context.
15. Chain-of-Thought Prompting
Reasoning improves when models generate intermediate steps.
Example:
Q: A train travels 60 km in 1 hour.
How far in 3 hours?
Let’s think step by step.
Output:
1 hour = 60 km
3 hours = 60 × 3
= 180 km
This dramatically improves reasoning accuracy.
16. Reinforcement Learning from Human Feedback (RLHF)
After pre-training, models are aligned using human preferences.
Process:
- Human ranking
- Reward model training
- Policy optimization
This helps models:
- Follow instructions
- Avoid harmful outputs
- Improve helpfulness
17. Fine-Tuning Strategies
17.1 Full Fine-Tuning
All parameters updated.
Expensive but powerful.
17.2 LoRA (Low-Rank Adaptation)
Only small adapter matrices are trained.
Benefits:
- Cheap
- Memory efficient
- Faster training
Example using Hugging Face PEFT:
from peft import LoraConfig config = LoraConfig( r=8, lora_alpha=32, target_modules=["q_proj", "v_proj"] )
18. Quantization and Efficient Inference
Large models are difficult to deploy.
Quantization reduces memory usage.
Precision | Memory Usage |
|---|---|
FP32 | High |
FP16 | Medium |
INT8 | Low |
4-bit | Very low |
Example with BitsAndBytes
from transformers import AutoModelForCausalLM model = AutoModelForCausalLM.from_pretrained( "llama", load_in_4bit=True )
This allows large models to run on consumer GPUs.
19. Challenges in Modern AI Training
Despite incredible progress, major challenges remain.

Fig 3. Challenges in Modern AI Training
19.1 Hallucinations
Models generate false information confidently.
Causes:
- Statistical prediction nature
- Weak grounding
- Ambiguous training data
19.2 Data Contamination
Benchmarks accidentally leak into training datasets.
This inflates evaluation scores.
19.3 Energy Consumption
Training giant models consumes:
- Massive electricity
- Water cooling resources
- GPU manufacturing resources
Sustainability is becoming critical.
20. Future Trends in Training Methodologies
The future of AI training is moving toward:
- Mixture-of-Experts (MoE)
- Retrieval-Augmented Generation (RAG)
- Sparse architectures
- Multi-modal learning
- Self-improving agents
- Synthetic data generation
21. Mixture-of-Experts (MoE)
Instead of activating the full model, only specialized subnetworks activate.
Benefits:
- Lower computation
- Larger parameter counts
- Better scalability
Example:
Expert 1 → Coding
Expert 2 → Math
Expert 3 → Translation
Only relevant experts activate.
22. Retrieval-Augmented Generation (RAG)
Models retrieve external information before generating answers.
Pipeline:
- User Query
- Retriever
- Knowledge Base
- LLM Response
Advantages:
- Reduced hallucinations
- Up-to-date information
- Domain specialization
23. Why Training Methodologies Matter
The quality of AI systems depends less on “magic” and more on engineering discipline.
Success comes from:
- Better data
- Better scaling
- Better infrastructure
- Better optimization
- Better alignment
The frontier of AI is increasingly becoming a systems engineering challenge rather than purely an algorithmic challenge.
Final Thoughts
Modern AI models are the result of extraordinary advances across:
- Distributed computing
- Optimization theory
- Data engineering
- Hardware acceleration
- Neural architecture design
Training methodologies define what models learn, while scaling determines how deeply they can reason and generalize.
As parameter counts continue to grow and architectures evolve, we are entering an era where AI systems are beginning to exhibit capabilities once thought impossible:
Join the DSA Program at CodeKerdos and learn Arrays, Linked Lists, Stacks, Queues, Trees, Graphs, and System Design through hands-on Java projects and interview-focused training.
- General reasoning
- Autonomous planning
- Tool usage
- Scientific discovery
- Multi-modal understanding
But with this power comes responsibility.
The next generation of AI research must focus not only on making models larger, but also:
- More efficient
- More interpretable
- More aligned
- More sustainable
- More trustworthy
The future of AI will not belong solely to the biggest models, but to the systems that combine intelligence, efficiency, reliability, and human-centered design.
And that future is already being built today.
Explore more insightful blogs on Generative AI, Prompt Engineering, Machine Learning, DevOps, and emerging technologies at CodeKerdos Blog to deepen your understanding of modern AI systems and industry-ready development practices.