Why Do So Many DevOps Engineers Struggle to Learn Go?
Many DevOps engineers eventually reach a point where they decide to learn a programming language beyond shell scripting. After researching the cloud-native ecosystem, they quickly discovered that Kubernetes is written in Go. Most Kubernetes Operators are written in Go. Popular CNCF projects such as Prometheus, Helm, and many cloud-native tools are either built in Go or heavily influenced by it. Naturally, Go becomes the language of choice for engineers who want to move beyond simply using Kubernetes and start building tools around it.
The learning journey usually begins with excitement. A course is purchased, a YouTube playlist is bookmarked, or a learning platform is opened. The first few modules introduce concepts such as Variables, Data Types, Arrays, Slices, Maps, Functions, Pointers, Structs, Methods, and Interfaces. Everything sounds relevant because these are the foundations of the language.
Then the examples begin.
An apple is stored in a variable. A list of fruits is stored in an array. A circle’s area is calculated using a function. A student object is created using a struct.
While these examples successfully explain the syntax, they often fail to answer the question that most DevOps engineers care about:
“How does this help me understand Kubernetes, Platform Engineering, SRE, or Kubernetes Operators?”
The reality is that these concepts are not academic exercises. They are the exact building blocks that power Kubernetes itself. Once these concepts are connected to real-world cloud-native systems, learning Go becomes significantly easier and far more enjoyable.
This article explains Go fundamentals through the lens of Kubernetes and modern DevOps engineering.
Variables: The Memory of an Application
Most programming courses describe variables as containers that store values. While technically correct, that definition rarely explains why variables matter.
A better way to think about variables is as the temporary memory of an application. Every piece of software needs a place to remember information while it is running. A monitoring platform needs to remember CPU usage values. A CI/CD pipeline needs to remember the Docker image tag currently being deployed. A Kubernetes controller needs to remember which resource it is reconciling.
Consider a real production incident. While troubleshooting, engineers constantly keep track of information such as pod names, namespaces, node names, restart counts, and resource utilization metrics. Applications do the same thing. Variables simply provide a structured way to remember information during execution.
In Kubernetes, variables are used everywhere. Whether Kubernetes is tracking a pod’s status, remembering a namespace name, or storing configuration values retrieved from the API server, variables act as the application’s short-term memory.
Understanding variables becomes much easier when they are viewed as information storage rather than abstract programming syntax.
Data Types: Why Different Information Needs Different Representations
Not all information is the same. A pod name is text. A replica count is a number. A node readiness status is either true or false. A CPU utilization percentage may contain decimal values.
Programming languages need a way to distinguish between different kinds of information because each type of information behaves differently. You cannot add two namespace names together, just as you cannot treat a readiness status as a sentence.
A useful analogy is a toolbox. A hammer, screwdriver, and wrench are all tools, but each serves a different purpose. Data types work in a similar way. They ensure information is stored and processed correctly.
Kubernetes itself contains hundreds of different data types. Resource names are strings. Replica counts are integers. Readiness conditions are booleans. Resource quantities have specialized formats. Understanding data types is less about memorizing terminology and more about understanding that different kinds of information require different handling.
Arrays and Slices: The Difference That Confuses Most Beginners
One of the most common questions among new Go developers is:
“Why does Go have both Arrays and Slices?”
At first glance, both appear to solve the same problem. Both store collections of data. Both can contain multiple values. Many beginners struggle to understand why two different structures exist.
The answer becomes clearer when viewed through Kubernetes.
Imagine an application that always needs to store exactly twelve months of data. The number of items never changes. In such situations, a fixed-size collection makes sense. This is essentially what an Array is. Once created, its size remains fixed.
Now consider Kubernetes. When an application requests Pods from the Kubernetes API server, does it know in advance whether it will receive ten Pods, one hundred Pods, or one thousand Pods?
The answer is no.
Cloud-native systems are dynamic by nature. Pods scale up and down. Deployments grow and shrink. Nodes join and leave clusters. The amount of data changes constantly.
This is where Slices become useful. Unlike Arrays, Slices can grow and shrink dynamically. They are flexible and adapt to changing amounts of information.
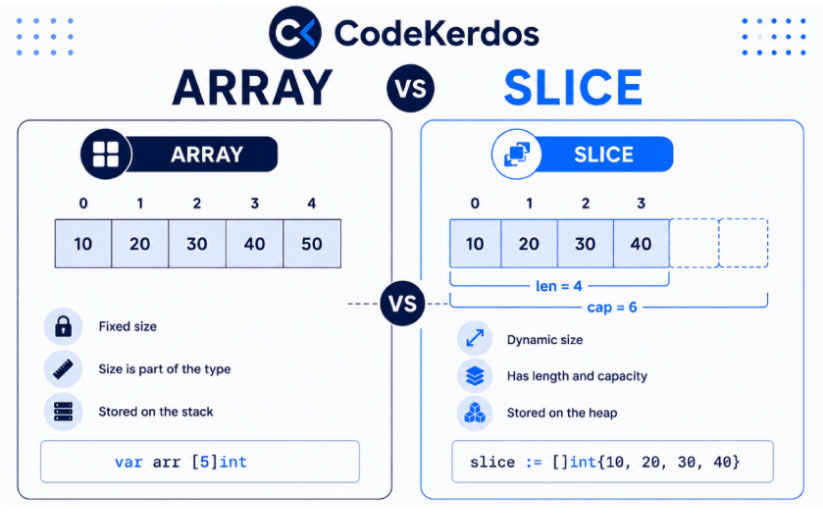
In fact, most Go developers spend far more time working with Slices than Arrays. Arrays still remain important because Slices are built on top of Arrays internally, but when building real-world applications, dynamic collections are usually more practical than fixed-size collections.
This is why Kubernetes developers frequently use Slices when dealing with Pods,
Nodes, Deployments, Services, and other cloud-native resources.
Maps: The Foundation of Fast Lookups
Maps are one of the most heavily used data structures in modern distributed systems because they allow applications to quickly retrieve information.
Think about a dictionary. Nobody starts reading from the first page every time they want to find a word. Instead, they jump directly to the relevant entry. Maps provide similar functionality to software.
One of the best Kubernetes examples of Maps is Labels.
When engineers apply labels such as:
This is why Kubernetes developers frequently use Slices when dealing with Pods, Nodes, Deployments, Services, and other cloud-native resources.
- app=payment
- environment=production
- team=platform
Kubernetes stores these values as key-value pairs.
When a Service needs to locate Pods belonging to a specific application, or when a controller needs to identify workloads associated with a particular team, Kubernetes can perform extremely fast lookups using these key-value relationships.
Without Maps, Kubernetes would need to repeatedly scan large collections of data, making operations significantly less efficient.
Once Labels, Annotations, Environment Variables, and Configuration Settings are viewed as Maps, the practical importance of this concept becomes obvious.
Operators and Control Flow: The Decision-Making Engine of Kubernetes
Every application makes decisions. In fact, software can be viewed as a collection of decisions executed continuously.
Consider airport security. A passenger arrives with a passport. Security personnel verify whether the passport is valid. If it is valid, the passenger proceeds. If it is not valid, further verification is required. This simple decision-making process is an example of control flow.
Applications behave in exactly the same way.
A login page checks whether credentials are valid. A monitoring platform checks whether CPU usage exceeds a threshold. An autoscaler checks whether additional resources are required.
Kubernetes itself is built around this concept.
Every controller within Kubernetes continuously compares the desired state against the current state. If both states match, no action is required. If they differ, corrective action is taken.
For example, if a Deployment specifies five replicas but only four Pods are running, Kubernetes detects the difference and creates an additional Pod. If a Pod crashes, Kubernetes notices the discrepancy and creates a replacement.
This constant cycle of observation, evaluation, and action is one of the most important concepts in Kubernetes, and it is fundamentally powered by control flow.
Functions: Packaging Work Into Reusable Actions
Functions are often introduced using mathematical examples such as calculating the area of a circle. While these examples demonstrate syntax, they rarely explain why functions are useful in production systems.
Functions exist because software frequently performs the same tasks repeatedly.
Imagine a coffee machine in an office. Employees simply press a button and receive a drink. They do not need to understand the internal sequence of operations because the machine already knows the required steps.
Functions provide the same abstraction in software.
A monitoring application may have a function that checks server health. A deployment platform may have a function that creates namespaces. A Kubernetes Operator may have a function that reconciles resources.
Instead of duplicating logic throughout an application, developers package related steps into reusable functions. This makes software easier to maintain, test, and understand.
Structs: How Kubernetes Represents Real-World Objects
Structs are where software begins to model real-world entities.
Many beginner tutorials use a Student example, but Kubernetes provides a much more relatable analogy for DevOps engineers.
A Pod is not a single value. It contains a name, namespace, labels, annotations, containers, resource limits, status information, and many other properties. All of these attributes belong together because they collectively describe a single resource.
A Struct is simply a way of grouping related information into one meaningful object.
This concept is everywhere in Kubernetes. Pods are Structs. Deployments are Structs. Nodes are Structs. Services are Structs. In fact, nearly every Kubernetes resource is represented internally using Structs.
When a YAML manifest is applied to a cluster, Kubernetes eventually converts that YAML into Go Structs so that it can work with the resource programmatically.
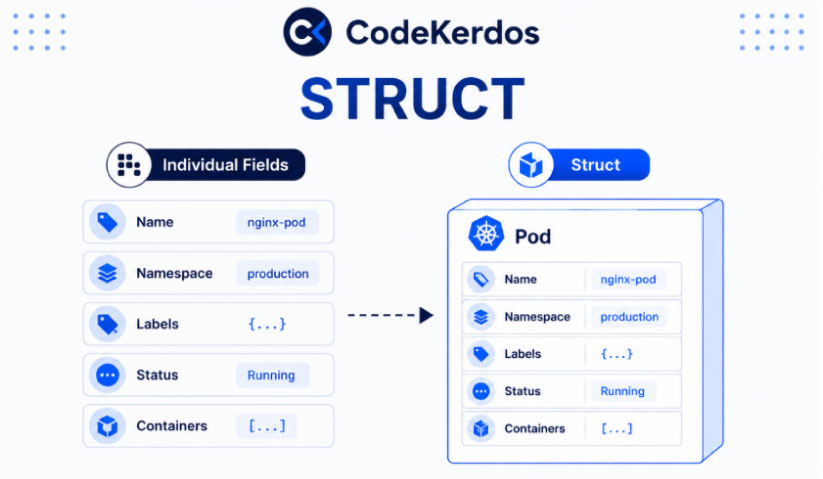
Understanding Structs is often the point where Go begins to feel directly relevant to Kubernetes engineering.
Pointers: Understanding Original Objects vs Copies
Pointers are often considered one of the most intimidating concepts in Go because they are frequently introduced through discussions about memory addresses.
A more practical way to understand Pointers is to ask a simple question:
Should a function work with the original object or a copy of the object?
Imagine handing a colleague a photocopy of a document. They can make changes, but those changes only affect the copy. The original remains untouched.
Now imagine handing them the original document. Any modifications directly affect the original.
Pointers allow applications to work with original objects rather than creating unnecessary copies.
This becomes particularly important in Kubernetes. Resources such as Pods, Deployments, and Nodes contain significant amounts of information. Repeatedly copying these objects would waste memory and processing resources.
This is why Kubernetes libraries such as Client-Go and Controller Runtime frequently rely on Pointers. They allow large objects to be manipulated efficiently without excessive duplication.
Pointers are not primarily about memory addresses. They are about efficiency and working with the correct version of an object.
Methods: Giving Objects Useful Behaviour
Structs allow applications to represent objects. Methods allow those objects to perform actions.
Consider a car. A car contains information such as model, color, fuel level, and engine size. However, a car is more than a collection of attributes. It can start, stop, accelerate, and brake.
Methods bring similar behavior to software objects.
A User object may authenticate. A Customer object may place an order. A Pod object may expose functionality that helps inspect its status or calculate resource utilization.
By keeping behavior closely associated with data, Methods make applications easier to organize and maintain.
Interfaces: The Secret Behind Kubernetes Extensibility
Among all Go concepts, Interfaces are arguably the most important for understanding how Kubernetes and modern cloud-native systems remain extensible.
A useful analogy is an electrical socket. Different devices can connect to the same socket because they follow a common standard. The socket does not care whether the connected device is a laptop charger, television, or phone charger. It only cares that the device follows the expected contract.
Interfaces apply the same idea to software.
Kubernetes supports numerous storage solutions, networking solutions, and cloud providers. Yet Kubernetes itself does not need specialized logic for every possible implementation.
Instead, Kubernetes relies on common contracts.
The design philosophy behind technologies such as Container Storage Interface (CSI), Container Network Interface (CNI), cloud integrations, and many Terraform providers closely mirrors the concept of Interfaces in Go. Different implementations can exist behind the scenes while presenting a consistent interface to the rest of the system.
Once this concept becomes clear, Interfaces stop feeling like an academic topic and start feeling like one of the most powerful tools in software engineering.
Why Learning Go Is Valuable for DevOps Engineers
Many DevOps engineers successfully automate infrastructure using Bash, Python, YAML, and existing cloud-native tooling. However, there comes a point where understanding how systems work internally becomes increasingly valuable.
Learning Go opens the door to building Kubernetes Operators, creating custom controllers, developing Prometheus exporters, contributing to CNCF projects, creating internal platform engineering tools, and even contributing directly to Kubernetes itself.
For engineers interested in Platform Engineering, SRE, Cloud Native Architecture, and Kubernetes internals, Go is not just another programming language. It is the language of the ecosystem.
The Key Takeaway
The challenge with learning Go is rarely the syntax itself. The challenge is understanding why these concepts exist and how they apply to real-world systems.
Variables act as application memory. Structs represent Kubernetes resources. Maps power labels and fast lookups. Slices manage dynamic collections of resources. Control Flow drives reconciliation loops. Functions package reusable logic. Pointers improve efficiency. Interfaces enable extensibility.
The fruit examples and circle calculations are not wrong. They simply fail to connect these concepts to the problems that DevOps engineers solve every day.
Once these concepts are viewed through Kubernetes and cloud-native systems, Go becomes significantly easier to understand and much more enjoyable to learn.
Frequently Asked Questions (FAQ)
No. Kubernetes can be used effectively without learning Go. However, engineers who want to build Kubernetes Operators, Custom Controllers, Admission Controllers, or contribute to Kubernetes projects will benefit greatly from learning Go because Kubernetes itself is written in Go.
Go offers excellent performance, strong concurrency support, simple syntax, efficient memory management, and easy deployment through static binaries. These characteristics make it ideal for distributed systems such as Kubernetes.
Both are valuable. Python is excellent for automation, scripting, and data processing. Go is particularly valuable for cloud-native tooling, Kubernetes development, Platform Engineering, and high-performance infrastructure applications.
Pointers and Interfaces are typically the most challenging concepts. However, when explained through Kubernetes resources, CSI drivers, CNI plugins, and cloud-native systems, they become much easier to understand.
Yes, although Slices are significantly more common. Arrays remain important because Slices are internally built on top of Arrays. Most production applications prefer Slices because they can dynamically grow and shrink.
Most DevOps engineers can learn Go fundamentals within a few weeks. Becoming comfortable with Kubernetes Operators, Controller Runtime, Client-Go, and production-grade application development typically requires several months of hands-on practice.
Continue Learning
Ready to go deeper into Cloud Native Engineering and Platform Engineering?
Continue with these resources:
Learn DevOps, Kubernetes, SRE, Agentic AI, System Design and Go with CodeKerdos
At CodeKerdos, learning goes beyond theory. Our focus is on helping engineers understand how technologies work in real production environments. Whether the topic is Kubernetes, DevOps, Site Reliability Engineering (SRE), Platform Engineering, Agentic AI, System Design, or go, every concept is taught using practical industry use cases rather than textbook examples.
If the goal is to move beyond tutorials and build real-world engineering skills, follow CodeKerdos and join a growing community of engineers building the next generation of cloud-native platforms.
About the Author
Debjyoti Maity is a Senior DevOps Engineer at Improving. He has extensive experience in Kubernetes, cloud infrastructure, observability, CI/CD, and production engineering. His current focus is on the intersection of DevOps and Agentic AI, helping engineers understand how AI-powered operational systems are transforming modern platform engineering and infrastructure operations.