A production alert fires at 11:47 PM.
Within seconds, Slack starts flooding with messages.
The API latency has suddenly increased. A few Kubernetes pods are restarting. Customers are reporting intermittent failures. Grafana dashboards are turning red.
An engineer opens Prometheus. Another starts checking Kubernetes events. Someone joins the incident bridge and begins searching logs. The DevOps team starts comparing recent deployments.
For the next forty minutes, highly skilled engineers spend most of their time doing something surprisingly repetitive:
Gathering context.
Not solving the problem yet. Not fixing production.
Just collecting information scattered across:
- Kubernetes
- logs
- metrics
- dashboards
- CI/CD pipelines
- cloud consoles
- incident channels
- deployment history
And this is exactly the operational bottleneck many companies are now trying to solve using AI agents.
Not because AI is trendy.
But because engineering systems have become too operationally complex for humans to investigate efficiently at scale.
This is one of the biggest shifts currently happening inside modern engineering organizations.
AI is no longer being treated only as a chatbot.
It is increasingly being designed as an operational investigation layer sitting alongside DevOps, SRE, and platform engineering teams.
The Most Successful Companies Are Not Building One Giant AI Agent
One of the first mistakes many engineering teams make when experimenting with AI agents is trying to build a single massive system that can do everything.
Initially, this sounds attractive.
One AI system connected to Kubernetes, logs, metrics, CI/CD pipelines, cloud APIs, dashboards, and internal documentation.
But once these systems touch real production environments, things become messy very quickly.
The AI starts consuming too much context. Logs become noisy. Operational reasoning becomes inconsistent. Different systems generate conflicting signals. And eventually the entire investigation workflow becomes unreliable.
The more mature engineering organizations are now moving toward a very different architecture.
Instead of building one giant AI system, they are building multiple smaller operational agents with highly specific responsibilities.
For example:
A Kubernetes agent may only understand:
- pods
- deployments
- namespaces
- scheduling
- events
- resource pressure
A logs agent may focus entirely on:
- log correlation
- anomaly detection
- failure pattern extraction
A metrics agent may specialize in:
- Prometheus analysis
- latency spikes
- infrastructure anomalies
- resource trends
Another agent may focus only on:
- deployment history
- CI/CD failures
- release changes
- rollback patterns
And above all of them sits something extremely important.
A supervisor agent.
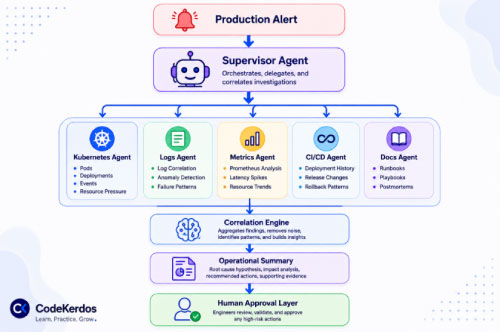
The supervisor does not investigate infrastructure deeply itself.
Its responsibility is orchestration.
When an operational event occurs, the supervisor decides:
- which agents should investigate
- what context should be shared
- which systems are relevant
- how findings should be correlated
- what should be summarized for humans
This architecture is becoming increasingly important because real-world operational investigations naturally break into smaller domains.
And interestingly, this looks very similar to how engineering teams themselves operate.
During incidents, infrastructure engineers, backend engineers, SREs, and platform teams all investigate different parts of the system simultaneously.
AI operational systems are beginning to mirror that structure.
How AI Agents Investigate Kubernetes Incidents in Parallel
Traditional operational investigations are surprisingly sequential.
An engineer checks logs. Then metrics. Then Kubernetes. Then deployments. Then networking.
But AI agents can investigate multiple operational domains simultaneously.
The moment a production issue occurs, specialized agents can begin parallel investigations.
One agent inspects Kubernetes events. Another checks pod restart patterns. Another compares deployment changes. Another analyzes observability metrics. Another reviews historical incidents.
Within minutes, and sometimes within seconds for smaller incidents, the supervisor agent starts correlating findings.
And instead of engineers manually gathering context for the first thirty minutes of an outage, the team immediately receives something far more useful.
An operational summary.
Something like:
“The production instability likely started immediately after the latest deployment. Kubernetes events indicate failed environment variable injection. Memory spikes appear secondary to repeated pod restarts.”
That changes the entire rhythm of incident response.
Engineers no longer begin investigations from zero.
The AI system acts as a first-response operational investigator.
And companies are realizing this can dramatically reduce:
- Mean Time To Resolution (MTTR)
- alert fatigue
- repetitive debugging
- operational context switching
- engineering overhead during incidents
If You Want To Use AI Agents in Production, Start Read-Only First
One of the biggest misconceptions around AI infrastructure systems is that companies are trying to make AI fully autonomous immediately.
In reality, the more experienced engineering organizations are doing the exact opposite.
They start with read-only operational agents.
The AI investigates. The AI summarizes. The AI correlates. The AI recommends.
But humans still approve critical production actions.
This design pattern is becoming extremely important.
Because production systems are noisy.
Logs can be misleading. Metrics can conflict. Kubernetes events can generate false operational assumptions.
And during long-running investigations, AI systems can occasionally:
- lose context
- over-prioritize noisy signals
- hallucinate correlations
- miss operational dependencies
The companies successfully adopting AI agents are treating them more like operational copilots rather than autonomous operators.
A typical workflow increasingly looks like this:
- AI investigates
- AI summarizes findings
- Human engineer reviews
- Human approves remediation
- AI continues monitoring
This approach gives engineering teams something extremely valuable.
Operational acceleration without losing human oversight.
And honestly, this is probably one of the smartest ways to introduce AI into production environments.
Because infrastructure trust should always be earned gradually.
The same way new engineers do not receive unrestricted production access on day one, AI systems also need carefully scoped operational boundaries.
Why Risky Code Execution Becomes a Serious Production Problem
One of the fastest ways to destroy trust in AI operational systems is allowing agents to execute risky production actions too early.
In demo environments, autonomous remediation looks impressive.
An AI detects a problem. It generates a fix. It executes the action automatically.
But real infrastructure environments behave very differently.
A single incorrect production action can become catastrophic.
Imagine an AI system accidentally:
- deleting Kubernetes resources
- scaling critical workloads incorrectly
- applying dangerous Terraform changes
- restarting the wrong services
- modifying ingress rules unexpectedly
- rolling back healthy deployments
An AI agent suggesting a rollback is useful.
An AI agent accidentally deleting a production namespace is catastrophic.
This is exactly why mature engineering organizations are becoming extremely careful about AI-generated infrastructure actions.
The more serious production systems now rely heavily on:
- dry-run execution
- sandbox environments
- scoped permissions
- namespace isolation
- audit trails
- approval workflows
- restricted APIs
- human checkpoints
Interestingly, this operational philosophy already feels very familiar to experienced DevOps engineers.
Because infrastructure engineering has always been built around blast-radius reduction.
The same principles are now being applied to AI operational systems.
Companies are realizing that the real challenge is not simply making AI agents capable.
It is making them operationally safe.
- whether the logs actually support the conclusion
- whether the deployment history matches the summary
- whether the metrics correlation makes sense
- whether the Kubernetes diagnosis is accurate
And honestly, that skepticism is healthy.
Because trust in operational systems is never created through marketing.
It is earned through reliability.
Companies experimenting with AI agents are quickly learning that transparency matters far more than “magic.”
Engineering teams want to know:
- why the AI reached a conclusion
- which systems it queried
- what logs it analyzed
- what metrics influenced reasoning
- which deployment changes were considered
This is why modern operational AI systems increasingly expose:
- reasoning traces
- investigation history
- tool execution visibility
- operational citations
- audit logs
- decision summaries
The companies successfully deploying AI systems internally are usually the ones making the AI explainable rather than mysterious.
Because once engineers can inspect how the AI reached conclusions, trust slowly starts increasing.
And operational trust is everything in production engineering.
Why Context Management Is the Biggest Challenge in Production AI Systems
One of the most interesting things companies are discovering is that the hardest part of operational AI systems is often not the AI model itself.
It is context management.
Modern infrastructure generates enormous amounts of operational data.
A single Kubernetes incident may involve:
- logs
- metrics
- traces
- deployment history
- ingress changes
- infrastructure drift
- networking events
- cloud provider alerts
- scaling activity
- dependency failures
And real production investigations may continue for hours.
This creates a major challenge for AI systems.
The longer the investigation continues, the more operational context the AI must maintain.
Engineering teams building production AI systems are already encountering practical issues such as:
- overloaded context windows
- excessive token costs
- repetitive investigation loops
- noisy operational data
- unreliable long summaries
- fragmented reasoning chains
This is why modern AI operational systems are increasingly becoming stateful.
And increasingly, companies are realizing that retrieval quality matters just as much as the model itself.
Because AI systems can only reason effectively on the operational context they actually receive.
If the retrieval layer surfaces noisy logs, incomplete deployment history, or irrelevant metrics, the entire investigation quality starts degrading.
This is why production AI systems are increasingly relying on:
- operational retrieval pipelines
- incident indexing
- observability summarization
- filtered context windows
- runbooks
- postmortems
- operational playbooks
- infrastructure knowledge retrieval
The companies succeeding with AI operations are usually the ones treating infrastructure knowledge as a first-class operational asset rather than simply sending raw logs into an LLM.
Instead of simple prompt-response interactions, companies are now building structured investigation workflows.
The AI system observes. It investigates. It delegates. It reevaluates. It gathers more evidence. It validates assumptions. Then it summarizes findings.
The workflow behaves much more like a graph than a conversation.
And this is exactly why frameworks like LangGraph are becoming increasingly important in infrastructure AI systems.
Because real operational investigations are rarely linear.
Why Observability for AI Systems Is Becoming a Huge Category
One of the most fascinating shifts happening right now is that engineering teams no longer only need observability for infrastructure.
Now they also need observability for the AI systems investigating infrastructure.
This creates an entirely new operational layer.
Companies increasingly want visibility into:
- why an AI agent made a decision
- which tools it used
- what logs influenced reasoning
- which metrics affected conclusions
- where investigations failed
- why recommendations changed
- how much context was consumed
- where token usage exploded
Without observability, operational AI systems quickly become dangerous black boxes.
And black boxes are unacceptable in production engineering.
This is why modern AI infrastructure systems are increasingly integrating tracing and observability layers specifically for AI workflows.
At the same time, companies are also becoming increasingly conscious about operational governance.
Because once AI systems begin participating in investigations across Kubernetes clusters, observability platforms, CI/CD systems, and cloud APIs, questions around:
- cost control
- token consumption
- data privacy
- access boundaries
- model governance
- infrastructure permissions
- auditability
suddenly become very important.
Many organizations are now experimenting with model-routing strategies where smaller models handle lightweight summarization while more capable models are reserved for complex operational reasoning.
This is becoming critical because production operational systems generate enormous amounts of logs, traces, and infrastructure data continuously.
Without careful governance, operational AI systems can become expensive surprisingly quickly.
Engineering teams want to replay investigations. They want audit trails. They want reasoning visibility. They want operational accountability.
Interestingly, many experienced DevOps and SRE engineers find these challenges very familiar.
Because in many ways, AI agents are starting to behave like distributed systems themselves.
They require:
- tracing
- observability
- debugging
- retries
- orchestration
- failure handling
- operational monitoring
Which is exactly why infrastructure engineers are becoming extremely important in the AI era.
The Best AI Systems Improve by Closing the Loop
One of the most interesting production lessons companies are learning is that operational AI systems cannot remain static.
The first version of an AI agent is rarely perfect.
Initially, the system may:
- misinterpret noisy logs
- over-prioritize irrelevant metrics
- generate incomplete summaries
- recommend weak remediation paths
- miss infrastructure dependencies
But the companies succeeding with operational AI are not treating these mistakes as failures.
They are treating them as feedback loops.
After incidents, engineers increasingly:
- annotate AI summaries
- reject incorrect conclusions
- improve operational playbooks
- refine investigation workflows
- add missing infrastructure context
- update remediation logic
Over time, the AI system slowly becomes aligned with the organization’s operational patterns.
This is becoming one of the biggest differences between toy AI demos and real production AI systems.
Real operational agents improve continuously through engineering feedback.
Incident history becomes organizational memory.
Operational investigations become training signals.
Previous outages become reusable context.
And gradually, the AI system starts understanding the infrastructure environment more deeply.
In many ways, companies are no longer just building AI tools.
They are building operational memory systems.
And that is a very important shift.
Because infrastructure teams already spend years accumulating operational knowledge through incidents, failures, postmortems, and troubleshooting patterns.
AI systems are now beginning to participate in that learning cycle.
Why DevOps Engineers Are Suddenly Becoming Critical for AI Systems
One of the biggest misconceptions right now is that operational AI systems are purely an AI problem.
But companies building these systems are quickly discovering something important.
The hardest part is not connecting an LLM.
The hardest part is understanding infrastructure.
An AI system cannot reliably investigate Kubernetes failures if the engineers building it do not deeply understand:
- Kubernetes scheduling
- networking
- observability
- deployments
- ingress behavior
- cloud infrastructure
- CI/CD systems
- operational debugging
This is why DevOps engineers, SREs, cloud engineers, and platform engineers are suddenly finding themselves at the center of AI infrastructure discussions.
Because these AI systems ultimately need operational intelligence.
And operational intelligence comes from infrastructure experience.
This is also why more infrastructure engineers are now learning:
- Python
- LangGraph
- tool calling
- MCP
- AI observability
- operational agent design
- AI workflow orchestration
- retrieval systems
- infrastructure knowledge pipelines
- operational memory architectures
Not because traditional DevOps skills are becoming irrelevant.
But because the future of infrastructure is increasingly becoming AI-assisted.
The engineers who understand both operational systems and AI workflows will likely define how modern infrastructure operates over the next decade.
The Future of Engineering Teams Will Not Be Humans vs AI
The companies succeeding with operational AI systems are not trying to replace engineers.
They are trying to reduce repetitive operational burden.
That distinction matters.
The goal is not removing humans from infrastructure.
The goal is allowing engineers to spend less time gathering fragmented operational context and more time solving meaningful problems.
AI agents are becoming valuable because they can:
- investigate faster
- summarize operational data
- correlate distributed systems
- reduce alert fatigue
- accelerate incident response
- assist debugging workflows
- retrieve operational knowledge
In many ways, operational AI systems are beginning to compress years of operational knowledge into reusable investigation workflows.
Previous outages become searchable context. Operational playbooks become machine-readable. Incident investigations become reusable organizational memory.
That is a very important shift.
Because infrastructure engineering has always depended heavily on institutional knowledge.
The engineer who remembers a similar outage from eight months ago often solves the problem faster than everyone else.
Now companies are beginning to build systems capable of preserving and operationalizing that knowledge continuously.
In many ways, we are entering the era of AI-native operational systems.
And honestly, this shift has already started.
The companies building these systems today are quietly redefining how engineering operations will work tomorrow.
And the engineers best positioned for this future are the ones who understand both infrastructure and AI systems.
That is exactly why more DevOps engineers are now starting to learn Agentic AI, operational workflows, LangGraph, observability, and AI-powered infrastructure systems.
Because modern infrastructure is no longer just about automation.
It is increasingly about intelligent operational systems capable of reasoning, investigating, and assisting engineering teams in real time.
Why More Engineers Are Learning Agentic AI at CodeKerdos
One of the biggest reasons infrastructure engineers struggle with Agentic AI is that most AI content online is still heavily focused on:
- generic chatbots
- prompt engineering
- isolated demos
- toy projects
- theory without operational depth
But production AI systems behave very differently.
Real operational AI requires understanding:
- Kubernetes
- observability
- incident response
- infrastructure debugging
- workflow orchestration
- operational safety
- stateful investigation systems
This is exactly why more DevOps engineers, SREs, cloud engineers, and platform engineers are now learning Agentic AI through infrastructure-first workflows.
At CodeKerdos, the focus is not just teaching “AI tools.”
The focus is understanding how modern AI operational systems are actually engineered.
That includes:
- Kubernetes diagnostic agents
- LangGraph workflows
- AI observability
- MCP integrations
- infrastructure-aware AI systems
- operational copilots
- Docker and Helm deployment
- production-safe AI workflows
Because the future of DevOps is not just writing automation scripts anymore.
It is designing intelligent operational systems that can reason, investigate, and assist engineering teams at production scale.
And the engineers who understand both infrastructure and AI workflows will likely become some of the most valuable engineering profiles over the next decade.
Connect With CodeKerdos
Learn more about advanced DevOps, Kubernetes, Agentic AI, operational AI systems, and infrastructure engineering at CodeKerdos.
Explore:
About the Author
Debjyoti Maity is a Senior DevOps Engineer and mentor at CodeKerdos with experience in Kubernetes, cloud infrastructure, observability, CI/CD, and production engineering systems. He focuses on the intersection of DevOps and Agentic AI, helping engineers understand how AI-powered operational systems are transforming modern platform engineering and infrastructure operations.